
THE LAB #73: How to Bypass Cloudflare in 2025
Scraping websites protected by Cloudflare bot protection with open source tools

During the career of any professional web scraper, sooner or later, the name Cloudflare pops out. Considering the websites that implement a bot protection mechanism, the San Francisco company holds approximately 80% of the market, according to Statista.
My gut feeling, also based on my experience in the field, is that the number is overestimated. Cloudflare sells several services besides bot protection, and especially in recent years, I have not seen this large gap with other vendors. But our only numbers are from Statista and Datanyze, so we must stick to them. This doesn’t change the issue's core: we must find a solution to bypass it when doing web scraping.
How Cloudflare works
Let’s see how Cloudflare works using the reviews page of Burger King on Indeed.com.
When I open the page using the Incognito Mode of my Brave browser, I can see that the Cloudflare Turnstile (the CAPTCHA-style alternative made in Cloudflare) has been solved and redirects to this waiting room page.

In the background, a back-and-forth of POST requests is made to Cloudflare endpoints, passing encrypted data in the Payload.
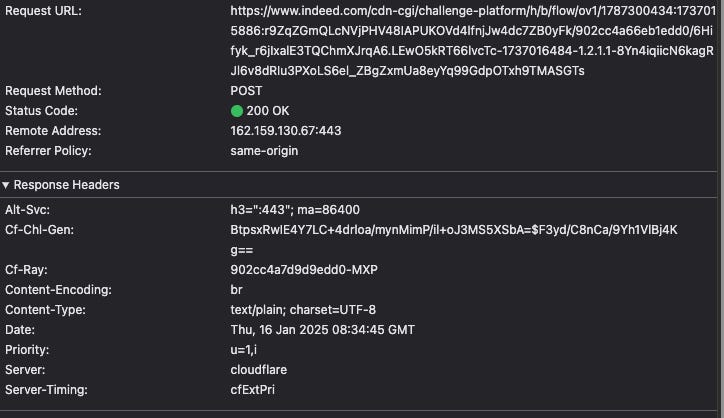

Even if we don’t know exactly what the payload contains, we can assume it’s our browser fingerprint, so there will be all the settings and parameters that, according to the Cloudflare algorithm, can signal a red flag in detecting bots, like the “webdriver flag” of the browser or hardware configuration.
Since my hardware and browser are totally legit, after all these challenges, I get the well-deserved cf_clearence cookie, signaling to the server that I can access the website.

In this case, the cookie is valid for six months, so theoretically, I can use it for half a year in my scrapers to access the website.

The reverse engineering approach
Now that we understand how Cloudflare works at a high level, we can understand why there have been so many attempts to reverse-engineer it. Programmatically obtaining the clearance cookie is a way to bypass every website protected by Cloudflare.
During these years, I’ve seen many open-source repositories like Cloudscraper trying this way, with a discrete fortune in some cases.
While developing these tools helps significantly in understanding how an anti-bot solution works and what signals are used to detect scrapers and consequently create an “invisible” one, this is an inefficient way to proceed if we’re stuck with a web data-gathering project. It takes time to deobfuscate the scripts used to generate the payload since it’s core for Cloudflare or any other anti-bot service to keep this process secret. Unless you’re working for a company with deep pockets, you’re playing an unfair game: you’re outnumbered, with less budget, and even if you can solve the enigma, you must restart almost from scratch as soon as the anti-bot gets updated. Last but not least, every anti-bot needs its own reverse-engineer process, making the creation of the “perfect undetected scraper” almost impossible since it’s so hard to keep pace with every release of the major anti-bot solutions.
Does this mean we need to give up?
Of course not! Reverse engineering anti-bot software is crucial for profoundly understanding what’s happening under the hood. Still, we need a different approach when we need to scrape data efficiently.
Behaving like a human
A different approach to creating the “perfect scraper” is to compare how a real browser looks from the server's perspective. Since all the browser APIs are public, we know what a “Windows Desktop with Chrome 131” looks like; we just need to recreate the exact digital fingerprint in our Playwright or Puppeteer scrapers.
It is not easy, but at least you are not starting from a blind spot, and you know your goal. This is what anti-detect browsers do: given a catalog of genuine fingerprints, they attach one of them to your scraping session, giving the illusion to the target website that the requests are coming from legit hardware instead of a data center, which in 99% of cases can be considered a huge red flag.
In cases where the anti-bot is configured with stringent rules, this can’t be enough since other variables enter the game, like keyboard and mouse behavior tracking, but it’s a good starting point for your projects.
How to scrape Cloudflare-protected websites in 2025?
Given all these premises, let’s see how, in 2025, we can use open-source tools to scrape data from Cloudflare-protected websites.
The same test using commercial tools will be performed later in the following months.
The script is in the GitHub repository's folder 73.CLOUDFLARE, which is available only to paying readers of The Web Scraping Club.
If you’re one of them and cannot access it, please use the following form to request access.
Given the Burger King review page on Indeed.com, let’s see which open-source tool can retrieve its HTML code.
Playwright ❌
Let’s start with a simple scraper in Playwright, with no patch and stealth library added.

Although I’m using a local instance of Brave Browser and some parameters to mask the usage of a browser automation tool, I cannot bypass the turnstile check.
from playwright.sync_api import sync_playwright
import time
CHROMIUM_ARGS= [
'--no-sandbox',
'--disable-setuid-sandbox',
'--no-first-run',
'--disable-blink-features=AutomationControlled',
'--start-maximized'
]
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/',channel='chrome',no_viewport=True,executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
all_pages = browser.pages
page = all_pages[0]
page.goto('https://www.indeed.com/cmp/Burger-King/reviews', timeout=0)
time.sleep(10)
browser.close()Cloudscraper ❌
We opened the article with this tool, but the repository has not been updated for two years.
I tried to open the page, but the only code I could see was on the turnstile page.
import cloudscraper
scraper = cloudscraper.create_scraper()
print(scraper.get("https://www.indeed.com/cmp/Burger-King/reviews").text) Botasaurus ✅
Botasaurus is a powerful web scraping framework written in Python. It also has a UI, a scheduler, and many other features not found in other tools.
