
How Scraping the Web Became an Expensive Business
How the industry moved from gathering low-hanging fruits to an expensive engineering challenge.


In 2024, large-scale web scraping is a structured, resource-intensive process, with costs carefully built into budgets. But it wasn’t always this way.
In the early days, scraping the web was simple, inexpensive, and full of untapped potential. Today, it’s a complex engineering challenge, shaped by years of advancements and countermeasures. This journey—from humble beginnings to a high-stakes industry—is a reminder of how much things have changed.
When I was Your Age
Back in 2009, scraping websites was so simple that data collection costs were practically zero.
My co-founder Pierluigi Vinciguerra and I first ventured into our web scraping garage project while working during the day at Accenture, where we handled large data warehousing projects for financial institutions. At the time, cloud computing didn’t exist, and “big data” mostly meant internal company systems like transactional databases and CRM platforms.

Internet proejcts leveraging “external” data like Google and Facebook were booming, and the idea of collecting data from the internet felt like untapped potential—so we gave it a try.
We started with real estate websites, using basic home internet connections and low-performance netbooks, those lightweight laptops popular in the late 2000s. Websites were just plain HTML back then: no JSON, no logins, no protection, and often built with similar structures.
Without Python libraries or tools, we turned to C++ and used Excel to speed up the process. I was an Excel "blackbelt"—I used it for almost everything! In minutes, we could identify the HTML tags, generate code, and set up daily scrapes. We targeted every real estate portal we could find, from Azerbaijan to Argentina.
And it worked. No blocks, no CAPTCHAs, no issues. Just clean data collected daily.
Within six months, we had the largest global catalog of real estate listings in Italy—and soon, the world. Though we initially aimed to sell the data to funds, we ended up working with research and marketing companies instead.
Our costs? A netbook, an internet connection, and a MySQL server hosted in Germany. Writing a scraper took under 10 minutes per website, making the data collection cost negligible. Even legally, scraping was largely unaddressed in terms of service agreements at the time.
Some of the most notable—and yes, more successful—examples of early web scraping come from companies like Google, Facemash (later Facebook), and Airbnb.
In 1996, Google began as a Stanford research project, using web scraping to index the internet. At the time, websites were relatively open, with few security measures against automated access, and the web itself was much smaller than today. These conditions allowed Larry Page and Sergey Brin to index the web globally using modest computational resources available at a university.
In 2003, Mark Zuckerberg launched "Facemash" while a student at Harvard. The site scraped student photos and names from the university's online facebooks—publicly accessible directories of student profiles. This straightforward scraping method required minimal resources and enabled him to populate the site with content rapidly. Facemash laid the groundwork for what eventually became Facebook.
Airbnb also relied on scraping in its early days to overcome the classic "chicken-and-egg" problem of building a marketplace. Its founders, Brian Chesky, Joe Gebbia, and Nathan Blecharczyk, scraped listings from Craigslist and invited hosts to cross-post their properties on Airbnb, jumpstarting their platform's growth.
These stories highlight how early web scraping, with its minimal costs and open access, helped lay the foundation for some of today’s most influential companies.
Enter the Maze
The arms race between scrapers and websites has transformed the industry into a high-cost, high-stakes game
Fast forward fifteen years, and things have gotten far more complicated. Websites now employ a range of measures to block, confuse, or deter scrapers. These efforts have driven up the cost of data extraction on multiple fronts, creating an escalating battle between scrapers and defenders.

The tools used to block scrapers are varied—some clever, others downright frustrating. These methods include everything from cloaking and IP blocking to CAPTCHAs and honey traps. While they aim to keep bots out while letting humans in, they often fail to strike the right balance, frustrating legitimate users and attackers alike.
One example of a creative, though rare, deterrent is the "honey trap" (also known as honey potting or bait data). This technique involves feeding fake data to bots to pollute their results. Over 15 years, I’ve read countless articles and blog posts about honey traps, often accompanied by worried inquiries from clients and partners. Yet, in all my experience, I’ve only encountered it once—and on a small, obscure website. Despite its rarity, the fear of honey traps has added layers of complexity and cost to quality assurance in web scraping.
CAPTCHAs, touted as the “end of scraping” when they first appeared, have proven too disruptive to user experience for widespread adoption on e-commerce websites. While they still exist, their usage has dwindled over time.
IP blocking, however, was a true game-changer. Websites began systematically banning IPs used repeatedly or originating from data centers. This effectively ended small-scale scraping operations, forcing scrapers to turn to proxy providers for residential IPs. Today, proxies have become an entire industry, mitigating IP bans but at a steep price.
The result? Scraping is still possible, but at much higher costs. Tasks that once cost $1 now cost $100, driving what could be considered B2B inflation. The complexity doesn’t stop at access: modern websites are packed with APIs, JSONs, and microservices, making even the basic act of identifying the right data a time-consuming task. Writing and maintaining a scraper now takes hours instead of minutes, thanks to this layered architecture.
The arms race between scrapers and websites has fundamentally transformed the industry, driving innovation but also skyrocketing costs.
The New Cost Structure
I like to split the activity into two main chunks: Finding the data, which involves writing code and identifying tags (often aided by AI, though not without issues), and Extracting it, which is ultimately a battle between antibot systems and unblockers or proxies.
Once you have the data, tasks like storage, quality checks, enrichment, deduplication, and matching become necessary. However, these steps are part of standard data pipelines and not exclusive to web scraping. To use an analogy from mining or oil extraction, this discussion focuses on getting the raw material out of the ground, not refining it.
Finding Data: A Matter of Talent
In software development, there’s often a hard way (writing code) and an easy way (using tools) to achieve a goal. The same applies to web scraping. Personally, I prefer well-written code over drag-and-drop tools—it’s harder to build, test, and debug but ultimately more robust and scalable.
The time it takes to write a scraper largely depends on the talent available. Skilled engineers can write and test code quickly, even if their hourly rates are higher. On the other hand, less experienced teams may take longer, leading to higher overall costs.
AI tools have started helping with scraper development, but they’re like Ferraris: in the hands of a skilled driver, they’re powerful; in the hands of a novice, they’re a dangerous hazard.
Extracting Data: A Matter of Money
Once your scraper is ready, running it is where costs begin to mount. Residential proxies, a popular method for bypassing IP blocks, often cost around $7 per GB of traffic. Let’s use this as a baseline to analyze the cost implications of a typical scraping operation.

Important: I am not entering in the debate of IF a residential proxy is needed for this website or IF alternatives to loading the entire web content, inclusive of media, is necessary. This is for illustrative purposes only
Suppose you wanted to scrape the entire catalog of Nike.com. Each product detail page transfers 5.4MB of data, and the website currently lists around 25,000 products. A full scrape would require transferring approximately 132GB of data, costing $923 at $7 per GB.
Scaling this to 10 countries with weekly updates? That would result in an annual proxy cost of nearly $480,000.
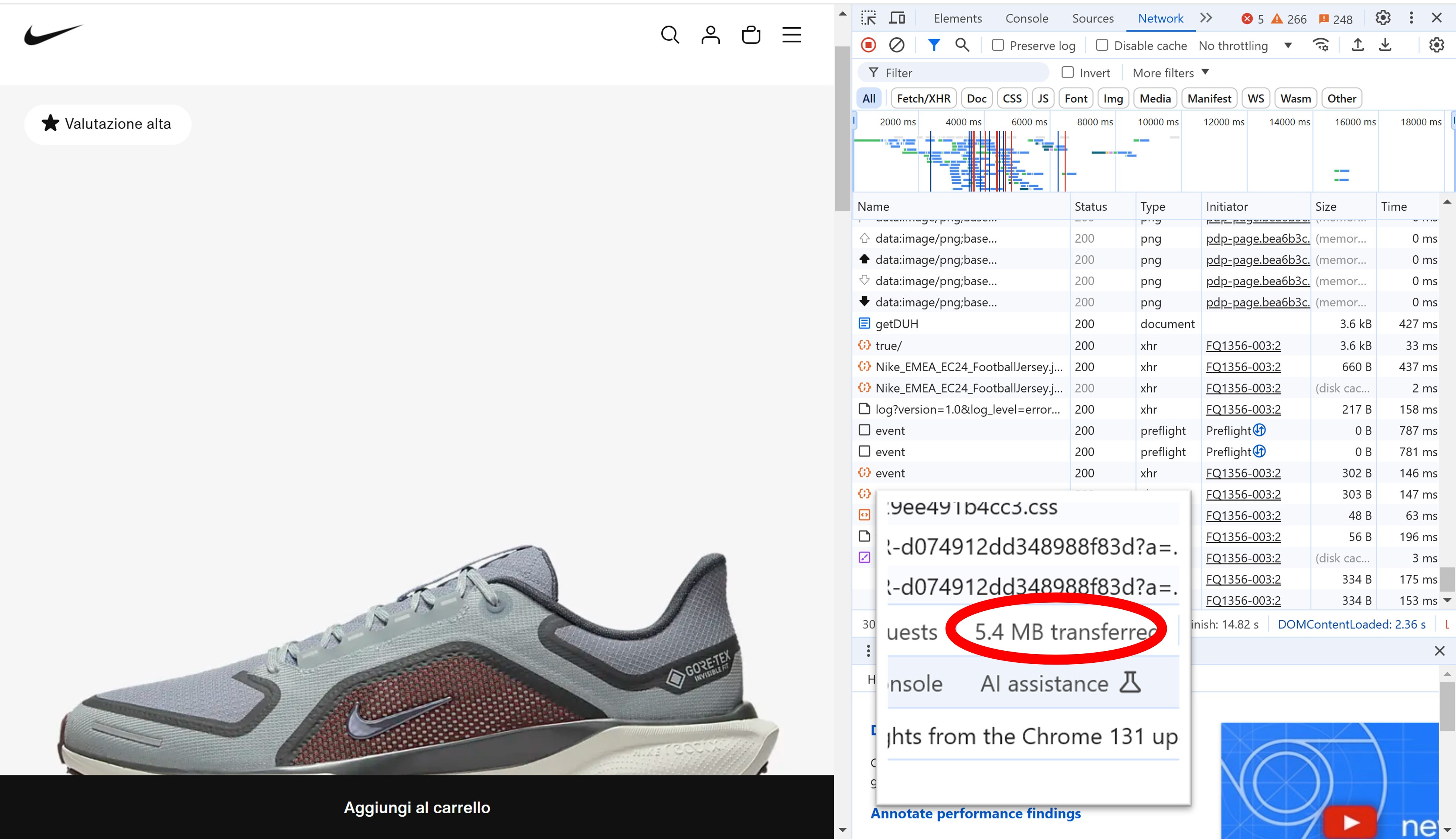
Experienced engineers can reduce these costs by over 99% through optimization: avoiding unnecessary data loads, minimizing bandwidth usage, or bypassing residential proxies entirely. But optimization requires expertise, which adds to upfront costs.
To date, AI scraping tools are not optimized for cost, so beware when you use them.
This example illustrates how a once-free activity has become a significant line item in modern data collection budgets.
An Educated Advice: Large-Scale Scraping is for Pros
While AI has lowered barriers to entry for coding, the technical landscape of web scraping has become increasingly specialized. Collecting data at scale now demands significant expertise, making it impractical for most businesses or startups to manage independently.
Small projects, prototypes, and side tasks can still be built in a garage, much like Google’s early days in the 1990s. However, the challenges faced by OpenAI to collect vast datasets for training ChatGPT are more reflective of today’s reality: large-scale scraping requires substantial investment in both talent and resources.
Fortunately, businesses don’t need to reinvent the wheel. Platforms like Data Boutique offer a practical solution by providing access to high-quality, pre-scraped datasets. These platforms eliminate the need for businesses to handle complex engineering or optimization, instead distributing extraction costs across multiple buyers and enabling data reuse. This approach makes data collection more affordable and accessible.
While these solutions may not cover every use case, they represent a significant evolution in the ever-growing and increasingly complex world of data extraction. For most businesses, leveraging these platforms is the smarter, more efficient path forward.
Great article! I love how you refer to Larry Page and Mark Zuckerberg. If you ever looking for a robust, reliable solution to scrape javascript heavy, anti-bot protected, or login wall protected sites, I suggest you to try Kameleo Anti-Detect Web Automation Browser: https://kameleo.io/web-scraping
We help you stay on top of the anti-bot game