
Hands On #6: Testing the Infatica web scraper
How Infatica's web scraper behave against the most used anti-bot solutions.
Hi everyone, this is a new series of posts from The Web Scraping Club, where I will try out products related to web scraping and make a sort of review about it. I hope this helps you to evaluate products before spending some money and time on testing them. Feel free to write me at pier@thewebscraping.club with any feedback and if you want me to test other products or solutions.
These Hands On episodes are not sponsored and the ideas expressed are my own, backed by quantitative tests, which change from the kind of product I’m testing. There might be some affiliate links in the article, which helps The Web Scraping Club be free and able to test even paid solutions.
Let’s continue our Hands-On series with another super proxy, the Infatica’s Web Scraper.
Just like the previous Unblocker tested on these pages, it’s a super proxy that promises to bypass most of the famous anti-bot solutions with a single API call.
Let’s see how it will perform on our usual test
What is the Infatica’s Web Scraper
Infatica.io is a Singaporean company born in 2019 as a proxy provider and launched recently its super proxy called Web Scraper.
It’s a relatively new product in their offering so, as we’ll see later, there’s still some room for improvements, but the features are more or less the usual ones we see in this type of solution.

There’s of course the Javascript rendering, IP rotation on Infatica infrastructure, the option to select the country of the IP to use, and to set custom headers and sections.
Our testing methodology
As we did to the other “unblocker” API, we’ll use a plain Scrapy spider that retrieves 10 pages from 5 different websites, one per each anti-bot solution tested (Datadome, Cloudflare, Kasada, F5, PerimeterX). It returns the HTTP status code, a string from the page (needed to check if the page was loaded correctly), the website, and the anti-bot names.
The base scraper is unable to retrieve any record correctly, so the benchmark is 0.
As a result of the test, we’ll assign a score from 0 to 100, depending on how many URLs are retrieved correctly on two runs, one in a local environment and the other one from a server. A score of 100 means that the anti-bot was bypassed for every URL given in input in both tests, while our starting scraper has a score of 0 since it could not avoid an anti-bot for any of the records.
You can find the code of the test scraper in our GitHub repository open to all our readers.
Preparing for the test
The first thing to do is to create an account on the Infatica.io website.
Keep in mind that if, after the test, you want to try any Infatica proxy plan, you can save some bucks by using the following discount codes reserved for our community:
Webscrapingclub10 - 10% discount on the first purchase of any proxy plan.
Webscrapingclub40 - 40% discount on the purchase of any proxy plan for 3 months.

You can have a 7-day trial with no commitment and then choose a monthly plan if you find it useful for your projects.
Setting up the Scrapy scraper
As said before, I’ve manually chosen fifty URLs, ten per website, as a benchmark and input for our Scrapy Spider.
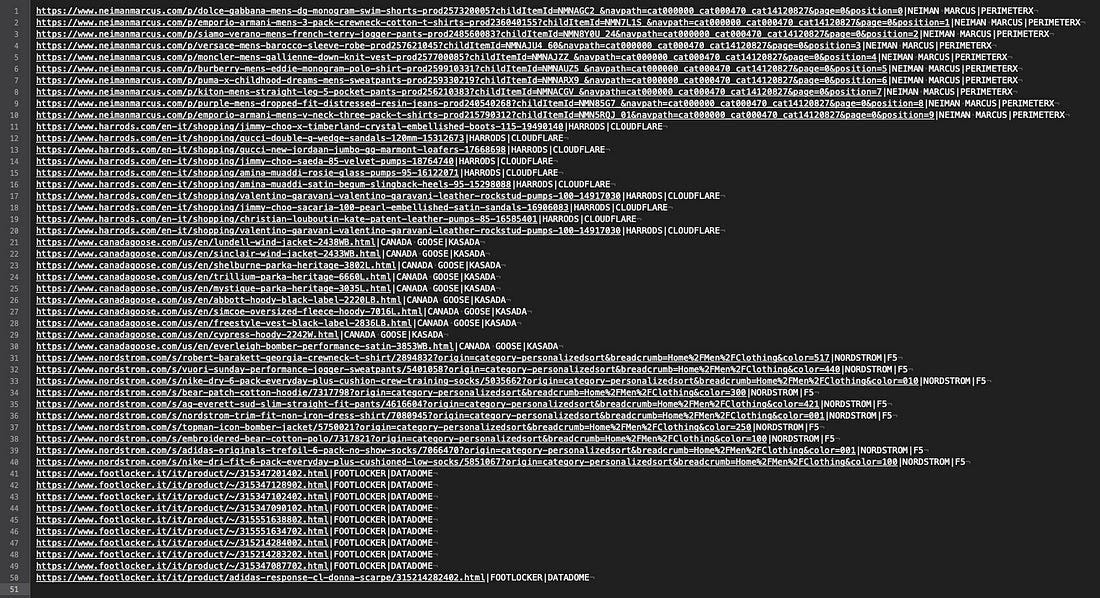
The scraper returns the Antibot and website names, given in input, the return code of the request, and a field populated with an XPath selector, to be sure that we entered the product page and were not blocked by some challenge.
There’s no particular configuration to apply to the scraper, only the call to a proxy in the settings.py file.
First run: no Infatica web scraper
With this run, we’re setting the baseline, so we’re running a Scrapy Spider without the site unblocker.
As expected, the results after the first run are the following.

Basically, every website returned errors except Nordstrom, which returned the code 200 but without showing the product we requested.
Second run: using the Web Scraper with only raw HTML requested
The HTML rendering, as we see from the documentation, is an option we can choose to enable. For this first run, I’m trying to bypass these anti-bots without it, just to test how the API is performing.
The only peculiarity of the Infatica solution is that we need to make an HTTP POST request to the Infatica endpoint, passing the desired URL in the payload, rather than requesting the URL itself.

While this is useful, since no additional packages are required to handle proxies in Scrapy, we need to think about it when we need the original URL in the results.
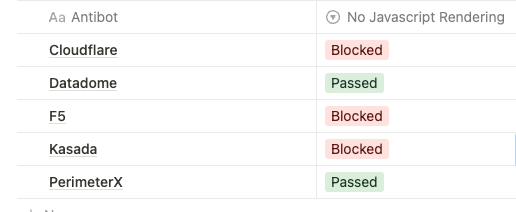
There’s no surprise in this result, of course, the Javascript rendering is one of the features needed to bypass the most sophisticated anti-bots, but we’re getting some good results with PerimeterX and Datadome.
Third run: the Web Scraper with Javascript rendering
To enable Javascript rendering we need to add it to the payload, as stated in the documentation.

And here are the results with the Javascript rendering enabled.

Kasada is the only anti-bot that can’t be bypassed but it’s also the less used one and since the Web Scraper is a relatively new product, it means that the solution can be implemented in the future
Final remarks
The Infatica Web Scraper is the latest super API for web scraping coming to the market in 2023, with the usual toolbelt of features:
Embedded proxy rotation
Javascript rendering
Session handling
Proxy-like integration
While it does not cover 100% of the anti-bot tested, it has a really competitive price, in fact, the smallest plan comes with 1$ per 1000 requests. Just to compare apples with apples, another similar product with the same pricing structure is the Bright Data web Unblocker. Despite being a much more mature product, it also costs 3 times more than Infatica’s web scraper.
Pros
Competitive Pricing
Easy integration with your scraper
Javascript rendering included in the basic price
Cons
There’s no pay-per-usage plan.
Rating
As we have seen, the Web Scraper passed all the tests for 4 anti-bots out of 5 after enabling the Javascript rendering. This means we can give 80/100 as a final score.