
Hands On #2: Testing the new Zyte Api
Is the new Zyte API capable to defeat Cloudflare, Datadome and other anti-bot solutions?

Hi everyone, this is a new series of posts from The Web Scraping Club, where I will try out products related to web scraping and make a sort of review about it. I hope this helps you to evaluate products before spending some money and time on testing them. Feel free to write me at pier@thewebscraping.club with any feedback and if you want me to test other products or solutions.
These Hands On episodes are not sponsored and the ideas expressed are my own, backed by quantitative tests, which change from the kind of product I’m testing. There might be some affiliate links in the article, which helps The Web Scraping Club be free and able to test even paid solutions.
In this issue, we’ll test the Zyte API, a tool that promises to make our life much easier when it comes to web scraping.
What is Zyte API
Zyte API, as the name says, is an API that, in the backend, handles the issues related to the anti-bot solutions when we scrape a website.
The core features of the solutions are:
automatic proxy rotation and their retries, switching also automatically from data center to residential when needed
a database of well known banning techniques and their anti-ban responses
geolocation
cookie jar for persistent cookies over different requests
sticky IPs per session, in case we don’t need rotation
a scriptable browser for rendering web pages and taking screenshots also
a web IDE to test all the parameters of the API

Our testing methodology
To test this kind of product I’ve developed a plain Scrapy spider that retrieves 10 pages from 5 different websites, one per each anti-bot solution tested (Datadome, Cloudflare, Kasada, F5, PerimeterX). It returns the HTTP status code, a string from the page (needed to check if the page was loaded correctly), the website, and the anti-bot names.
The base scraper cannot retrieve correctly any of the records and this will be our benchmark result.
As a result of the test, we’ll assign a score from 0 to 100, depending on how many URLs are retrieved correctly on two runs, one in a local environment and the other one from a server. A score of 100 means that the anti-bot was bypassed for every URL given in input in both tests, while our starting scraper has a score of 0 since it could not avoid an anti-bot for any of the records.
You can find the code of the test scraper in our GitHub repository open to all our readers.
Preparing for the test
Create an account on the Zyte’s website and request a trial for the API
First of all, you need to create an account on Zyte’s website and request a trial for the API.
After the trial is activated, you will find the Zyte API tab on the left of the screen.

Setting up the Scrapy scraper
As said before, I’ve manually chosen fifty URLs, ten per website, as a benchmark and input for our Scrapy spider.
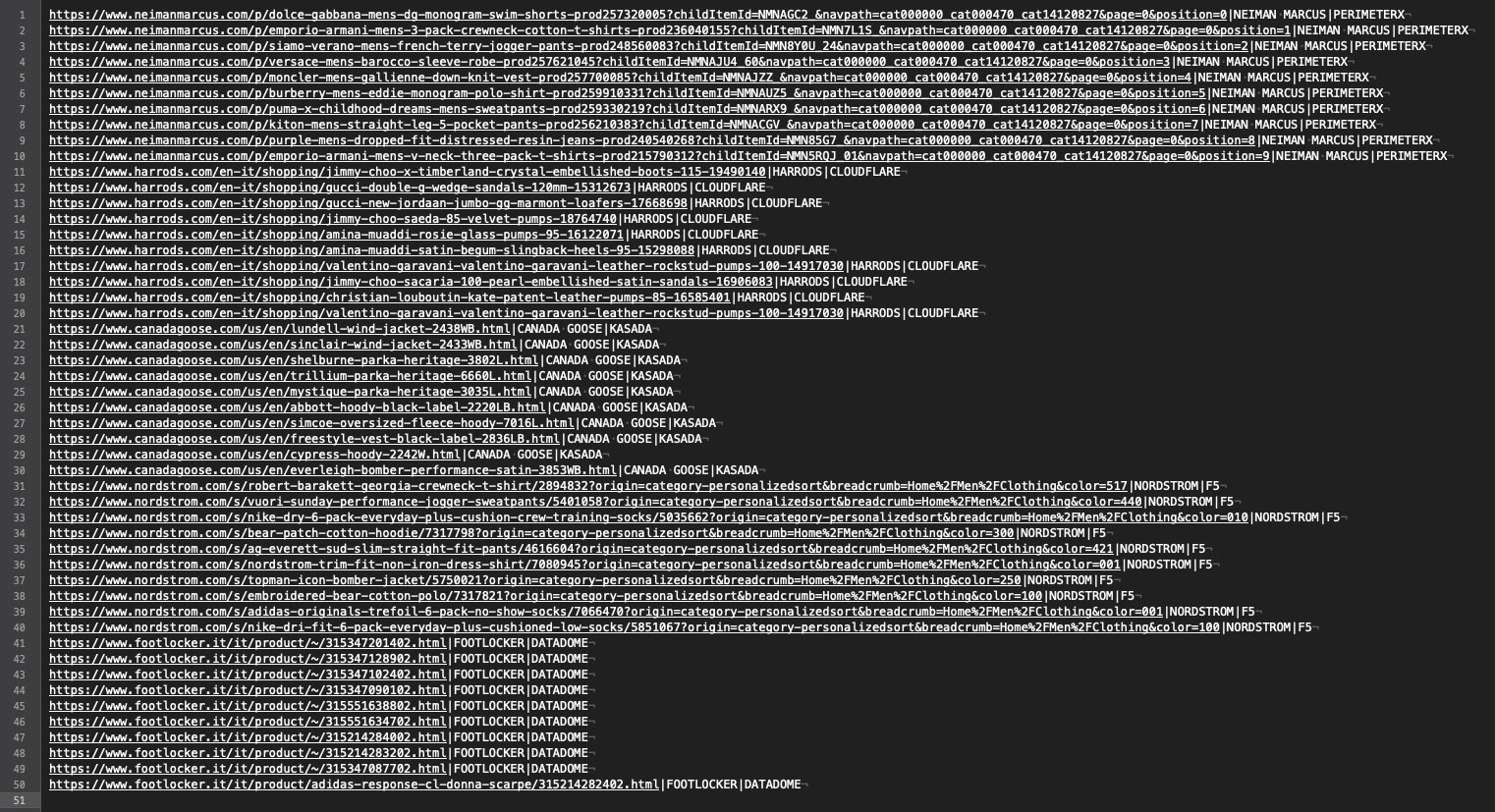
The scraper basically returns the Antibot and website names, given in input, the return code of the request, and a field populated with an Xpath selector, to be sure that we entered the product page and were not blocked by some challenge.
While being an API I could test it via Curl or Python requests, I wanted instead to integrate these calls in my Scrapy project, so I needed to install via pip also the package scrapy-zyte-api.
Following the instruction, on the GitHub repository the integration has been straightforward, just needed to add the following options in the setting.py file.
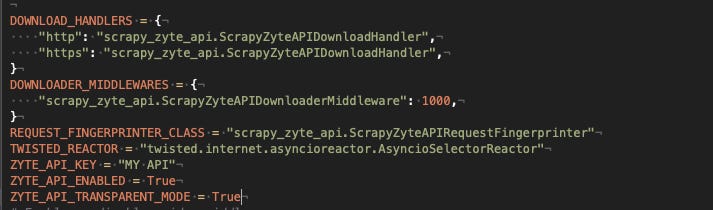
You can find anyway the full code of the scraper on the free GitHub repository of The Web Scraping Club.
First run: no Zyte API on local environment
With this run, we’re setting the baseline, so we’re running a Scrapy spider without any aid from Zyte API.
The results after the first run are the following.

Basically, every website returned errors except Nordstrom, which returned the code 200 but without showing the product we requested.
Second run: using the Zyte API with only raw HTML requested
This is the base usage of the Zyte API, called transparent mode. Basically, we’re using the API out of the box, without a browser rendering the pages.
Having made all the setup in the settings.py file, the scraper is pretty basic.
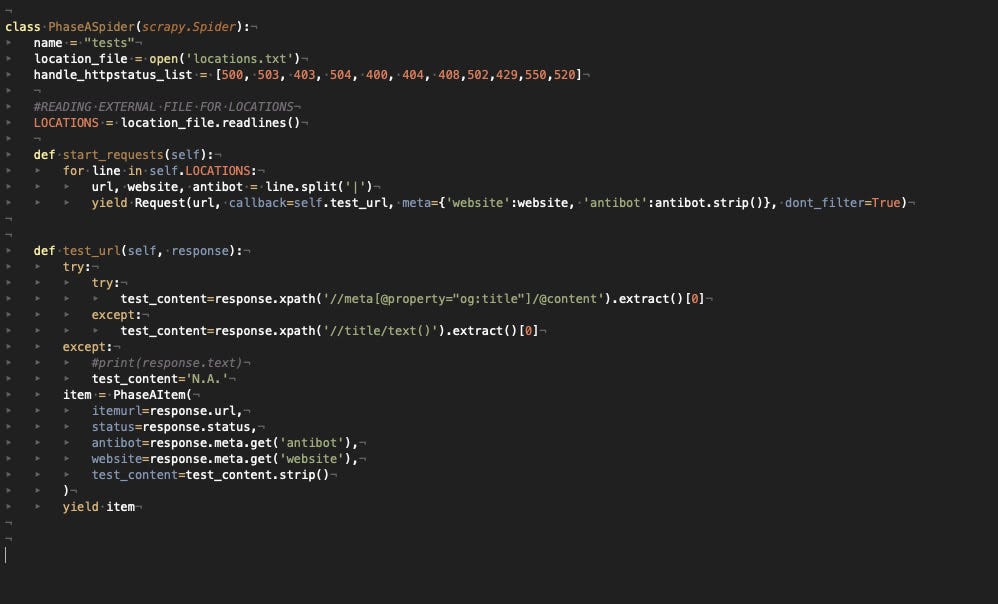
Here are the results.
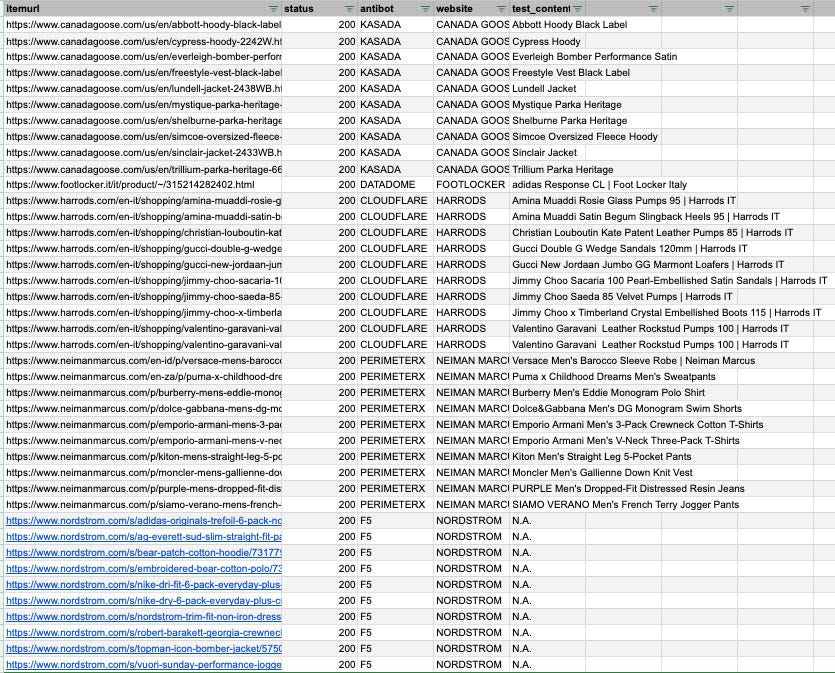
While we have a 100% success rate against Kasada, Cloudflare, and PerimeterX, we have issues against Datadome and F5. Let’s see if we get better results with the HTML rendered via browser.
Third run: using the Zyte API with browser rendering
To enable the browser rendering, the only thing to do is to review the requests parameter as follows.

Here are the results, with a stunning 100% success rate for all the websites.
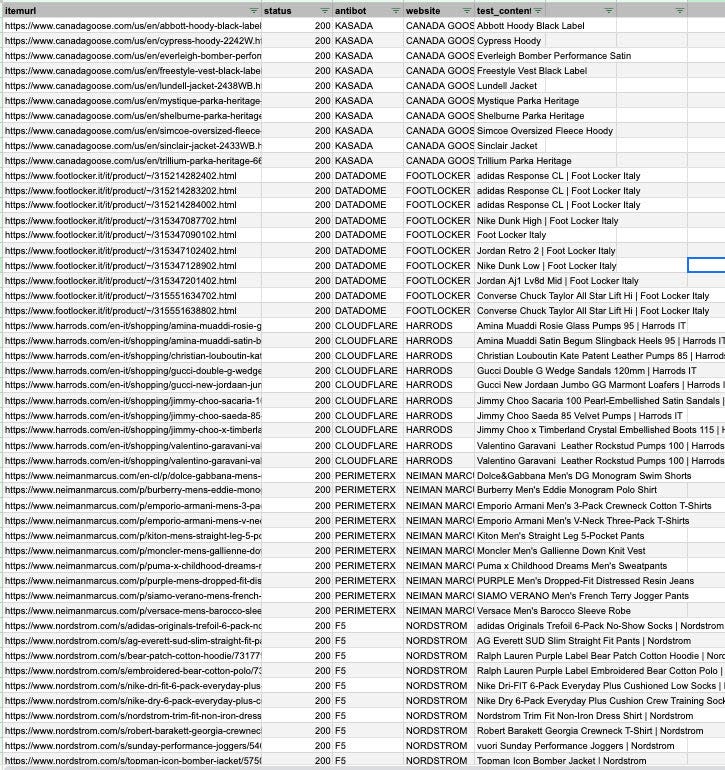
Final remarks
I’m really impressed by the Zyte API, when I first heard about it at the 2022 Extract Summit I was just curious about it but I thought it would have been difficult for it to tackle all the anti-bot around. But for the moment, the mission is accomplished!
Something worth noting is that from the web dashboard, you have the recap of your requests, and for each of them there is its cost, so you can make some cost projections before activating the API on the whole website. If you’re willing to try the Zyte API by yourself, you can claim $25 free credit following this link.
Pros
Integration with Scrapy is straight-forward
100% success rate
Giving the user the option if activate or not the browser rendering makes it more affordable on larger volumes.
Cons
At the moment, up to 25$ there's no monthly commitment, while if you plan to spend more, you need to set up a spending limit and pay upfront half of it. I’d prefer a plan with no monthly commitment even for a higher quota but, from Zyte’s perspective, it’s understandable they need to have a forecast of the usage of resources.
Rating
Since the Zyte API solved 31 out of 50 URLs in the first run, and 50 out of 50 in the second one, its final score should be 81/100 but in this case is not the right value, since on the first run we used only half of the potential of the API.
Since at full potential several runs always returned all the records, the real score is 100/100.
They advertise a feature to set a spending limit, but there is no option. I contacted support, sent a screenshot, they said there is no spending limit without a subscription. The entire system is designed to steal your money. I woke up yesterday to a bill 40x times more than what was expected. Support is unhelpful and they don't care, they just want to steal your money. Zyte is designed to be misleading.