Infinite scrolling isn’t just bad for you because of doomscrolling, it’s also a headache for your scraping scripts. The reason is that it involves highly dynamic content loading and, to make things worse, browser automation tools don’t offer methods for scrolling out of the box.
In this post, I’ll show you how to tackle that problem with a step-by-step solution for handling infinite scrolling in Playwright (and in Selenium and Puppeteer, too!).
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
Infinite scrolling, also known as "infinite scroll," is a web design pattern where new content loads automatically as the user scrolls down the page.
That’s extremely popular in mobile apps and has become increasingly common on the web as well, largely due to the widespread adoption of mobile-first design principles.
It works by detecting when the user is near the bottom of the current content and then dynamically loading more items using JavaScript, typically through AJAX requests made directly in the browser.
This interaction is so widely adopted that, according to Infinite Scroll Usage Statistics, over 516,000 live websites use infinite scroll via jQuery alone (which is far from a modern framework, to say the least). So, the actual number of implementations is likely much higher.
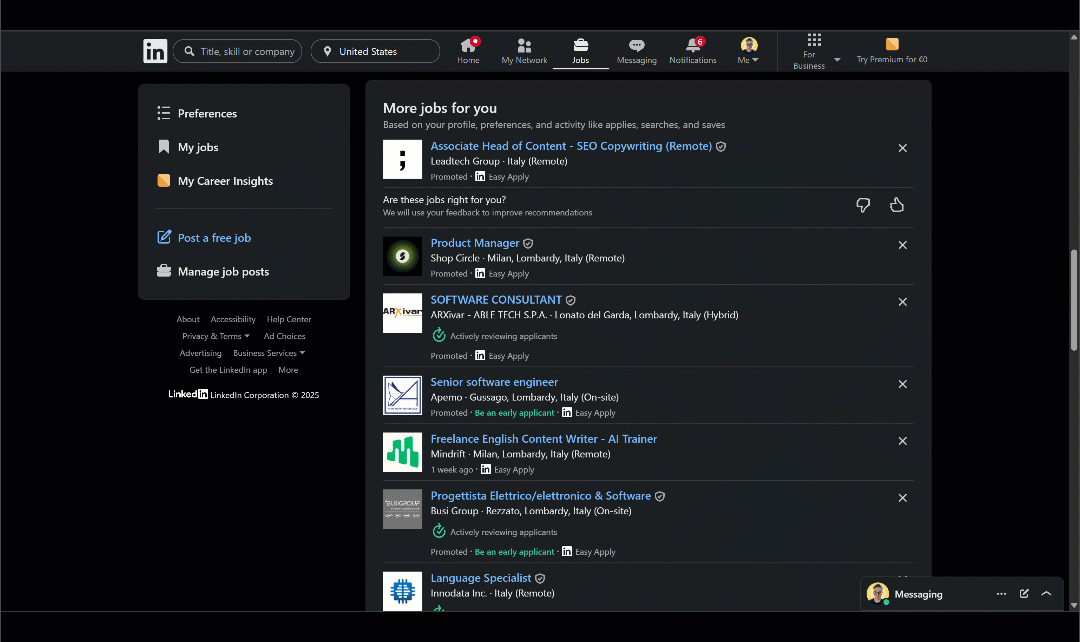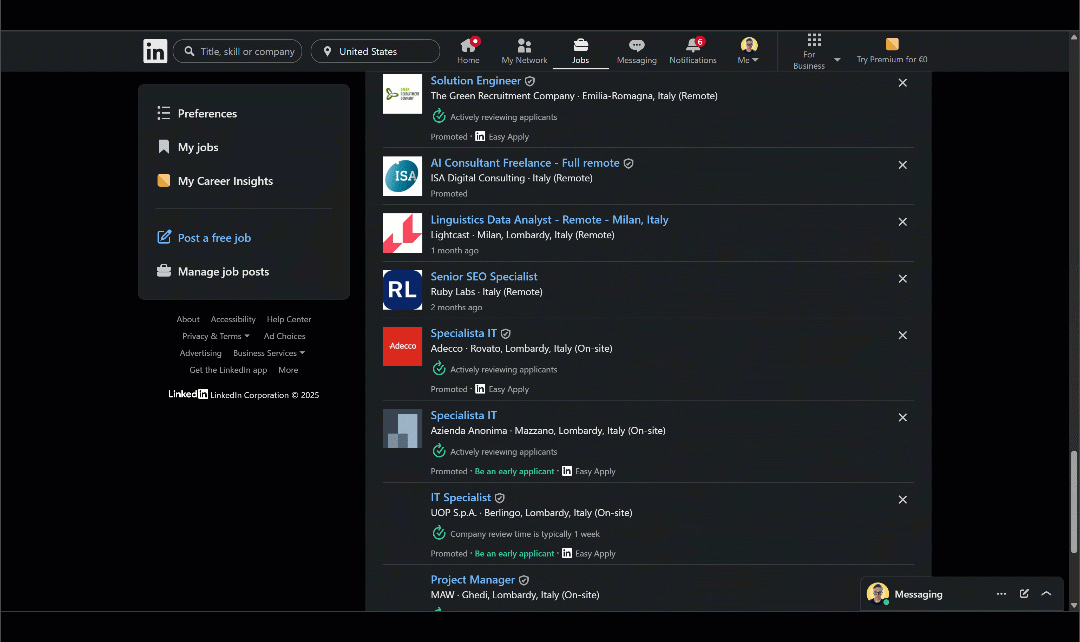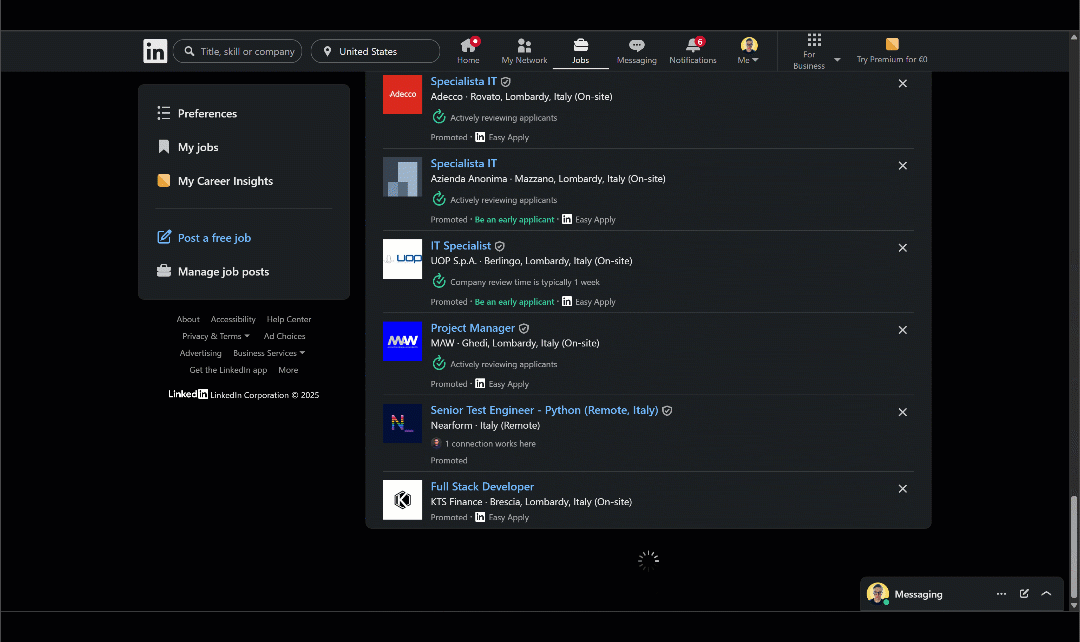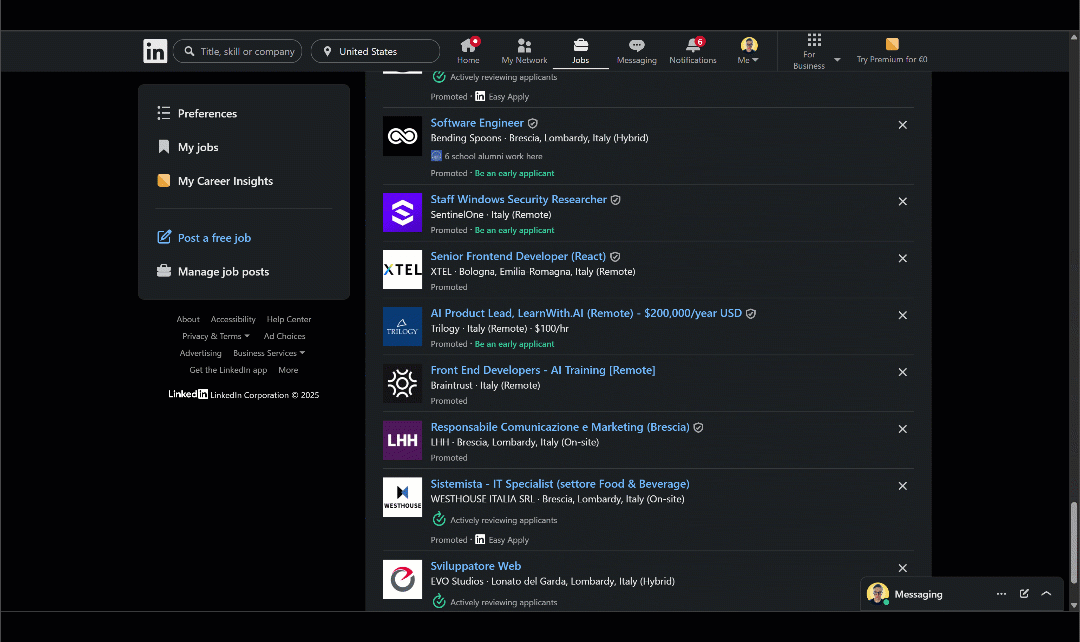
One well-known platform that uses infinite scrolling? LinkedIn!
The infinite scrolling pattern in action in LinkedIn
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
The Challenge of Dynamic Data Loading via Infinite Scroll in Web Scraping
Infinite scrolling is undoubtedly a challenge in web scraping for at least two main reasons:
It relies heavily on JavaScript, which requires a browser automation tool to execute and interact with the page.
Browser automation tools generally don’t provide built-in scrolling methods. In other words, their APIs typically don’t expose simple methods like scroll(). So, you need to simulate scrolling manually in other ways (spoiler: via a custom JS script).
Even if you successfully simulate scrolling, there’s still a major hurdle. You must wait for the dynamically loaded content to appear before scraping it. And that’s a challenge on its own!
If you don’t handle the waiting logic correctly, you risk scraping only part of the data or hitting issues where the content hasn’t finished rendering. That’s exactly why dealing with infinite scroll is so tricky (but don’t worry, there’s a solution!)
Automated JavaScript Script for Infinite Scrolling Interaction
Since browser automation tools generally don’t provide built-in scrolling methods, you need to define custom JavaScript logic to handle scrolling interactions. That's because, all major browser automation solutions (Playwright, Puppeteer, Selenium, etc.) allow you to inject and execute JavaScript directly within the page.
To simulate the scrolling behavior as a human would (e.g., scrolling to the bottom repeatedly to trigger dynamic loading), you can use the following JavaScript scroll automation script:
async function scrollPage(numScrolls = 20, delay = 500) {
// perform maxScrolls scrolls
for (let i = 0; i < numScrolls; i++) {
// scroll to the end of the page
window.scrollBy(0, document.body.scrollHeight);
// wait dealy ms before performing a new scroll
await new Promise(resolve => setTimeout(resolve, delay));
}
}
// start scrolling
scrollPage();
This JS script scrolls down to the bottom of the page 20 times, pausing for 500 milliseconds between each scroll.
To test it, open a page that relies on the infinite scrolling interaction. For example, in this post, I’ll refer to Infinite Scrolling e-commerce page from ScrapingCourse. Visit the page in the browser, right-click, select the “Inspect” option to open your browser’s DevTools, paste the script into the “Console” tab, and press Enter.
You should see the page automatically scrolling and loading more products like this:
See how the JS script leads the page to load new products via automated scrolls
As you can tell, the script successfully performs the automated scrolling needed to trigger dynamic content loading on the page.
Complete Infinite Scrolling Scraping Scenario
In this guided section, I’ll teach you how to scrape data from a site that uses infinite scrolling. Again, the target page will be ScrapingCourse's Infinite Scrolling page:
The target page
The browser automation tool used to interact with the page will be Playwright, and the programming language will be Python. Still, note that you can easily adapt the script to Selenium in Python or Playwright (or Puppeteer) in JavaScript.
To speed things up, I will assume you already have a Python project set up with Playwright installed. Specifically, I assume you already have a Python script like this:
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Initialize the Chromium browser
browser = await p.chromium.launch(
headless=False # Useful to see what is going on
)
page = await browser.new_page()
# Scraping logic...
# Close the browser and release its resources
await browser.close()
# Run the scraping logic
asyncio.run(run())
Now, let’s see how to handle infinite scrolling in a real-world scraping scenario using Playwright with Python!
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Enter the TWSC community at this link.
This tells Playwright to direct the browser it controls (Chromium in this case) to navigate to the URL specified as an argument to the goto() function.
Great! Time to apply automated scrolling to load all the data before scraping it.
Step #2: Run the JS Scroll Automation Script
Execute the JavaScript scroll script presented earlier as follows:
js_scroll_script = """
const maxScrolls = 20;
const delay = 500;
const scrollAmount = document.body.scrollHeight;
function wait(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function scrollPage() {
for (let i = 0; i < maxScrolls; i++) {
window.scrollBy(0, scrollAmount);
await wait(delay);
}
}
scrollPage();
"""
await page.evaluate(js_scroll_script)
The evaluate() function runs the given JavaScript code inside the browser context controlled by Playwright. Basically, it’s the same as running that JS code directly in the browser’s console, just like I demonstrated earlier to show how the script affects the page.
Amazing! New products will now appear on the page.
Step #3: Wait for the Product Elements to Load
Now, the evaluate() function waits for the JavaScript script to finish its execution (basically it waits until the last line of the script runs), which usually takes only a few milliseconds. However, the actual impact on the page takes longer (up to many seconds) because new products keep loading dynamically after each scroll.
As a human browsing the page, you’d naturally wait for new products to appear before interacting with them. Automating that waiting is challenging, and there are several possible approaches. Here, I’ll show a basic—yet effective—method I personally use in situations like this.
In most cases, each scroll triggers a predictable action. For example, on this page, 12 new products load on every scroll (so the number increases by 12 each time, with the last scroll that may load fewer).
So, to verify that the page has finished loading all the products you’re interested in, you can wait for the N-th product to appear on the page.
Start by inspecting a product's HTML element:
Note the HTML structure of the product element list
Notice that the CSS selector for each product is:
.product-item
To select the N-th product, you can use:
.product-item:nth-of-type(N)
Suppose you want to scrape the first 185 products. You can write:
By default, locator() waits up to 30 seconds for the specified element to be on the page (which is enough for this scenario). If you need to wait longer, you can specify a timeout like this:
await page.locator(".product-item:nth-of-type(185)").wait_for(timeout=60000) # waits up to 60 seconds
Great! You’ve now handled dynamic content loading, which is often the trickiest part of working with infinite scrolling in browser automation tools.
Note: Another, more complex approach involves intercepting the AJAX requests made by the page and waiting for them to complete. This method is not supported by all browser automation tools and comes with its own challenges. For example, after the network requests finish, the page still needs to use JavaScript to render the retrieved content. Thus, the completion of network requests doesn’t mean that the page has fully finished loading.
Now that you’re sure all product elements are on the page, prepare to scrape them all. Start by inspecting a single product element to understand how to define the selector and extract the data:
Note the HTML of a product element
Then, scrape all products using the following code:
product_elements = await page.query_selector_all(".product-item")
# Where to store the scraped data
products = []
# Scrape data from each product item
for product_element in product_elements:
name_element = await product_element.query_selector(".product-name")
name = await name_element.inner_text() if name_element else ""
image_element = await product_element.query_selector(".product-image")
image = await image_element.get_attribute("src") if image_element else ""
price_element = await product_element.query_selector(".product-price")
price = await price_element.inner_text() if price_element else ""
url_element = await product_element.query_selector("a")
url = await url_element.get_attribute("href") if url_element else ""
# Collect the scraped data
product = {
"name": name,
"image": image,
"price": price,
"url": url
}
products.append(product)
Wonderful! Mission complete.
Step #5: Complete Code and Execution
Put it all together, and you’ll get:
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Initialize the Chromium browser
browser = await p.chromium.launch(
headless=False # Useful to see what is going on
)
page = await browser.new_page()
# Go to the infinite scrolling page
await page.goto("https://www.scrapingcourse.com/infinite-scrolling")
# Execute the JS-based scroll logic
js_scroll_script = """
const maxScrolls = 20;
const delay = 500;
const scrollAmount = document.body.scrollHeight;
function wait(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function scrollPage() {
for (let i = 0; i < maxScrolls; i++) {
window.scrollBy(0, scrollAmount);
await wait(delay);
}
}
scrollPage();
"""
await page.evaluate(js_scroll_script)
# Wait for all content to load
await page.locator(".product-item:nth-of-type(185)").wait_for()
# Select all product items
product_elements = await page.query_selector_all(".product-item")
# Where to store the scraped data
products = []
# Scrape data from each product item
for product_element in product_elements:
name_element = await product_element.query_selector(".product-name")
name = await name_element.inner_text() if name_element else ""
image_element = await product_element.query_selector(".product-image")
image = await image_element.get_attribute("src") if image_element else ""
price_element = await product_element.query_selector(".product-price")
price = await price_element.inner_text() if price_element else ""
url_element = await product_element.query_selector("a")
url = await url_element.get_attribute("href") if url_element else ""
# Collect the scraped data
product = {
"name": name,
"image": image,
"price": price,
"url": url
}
products.append(product)
# Print the resulting scraped data
for p in products:
print(p)
# Close the browser and release its resources
await browser.close()
# Run the script
asyncio.run(run())
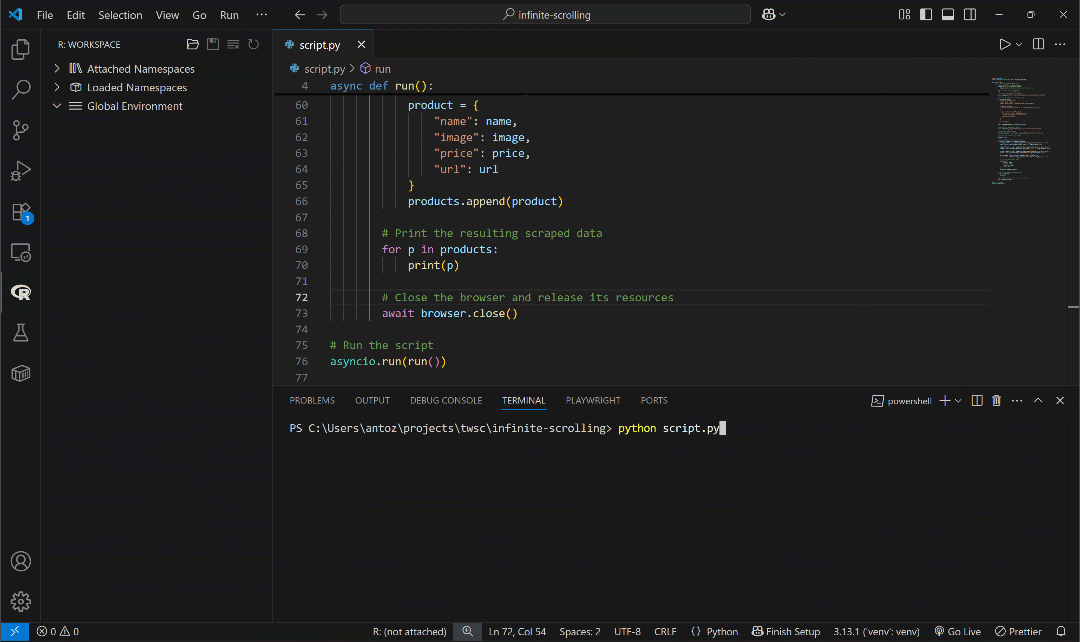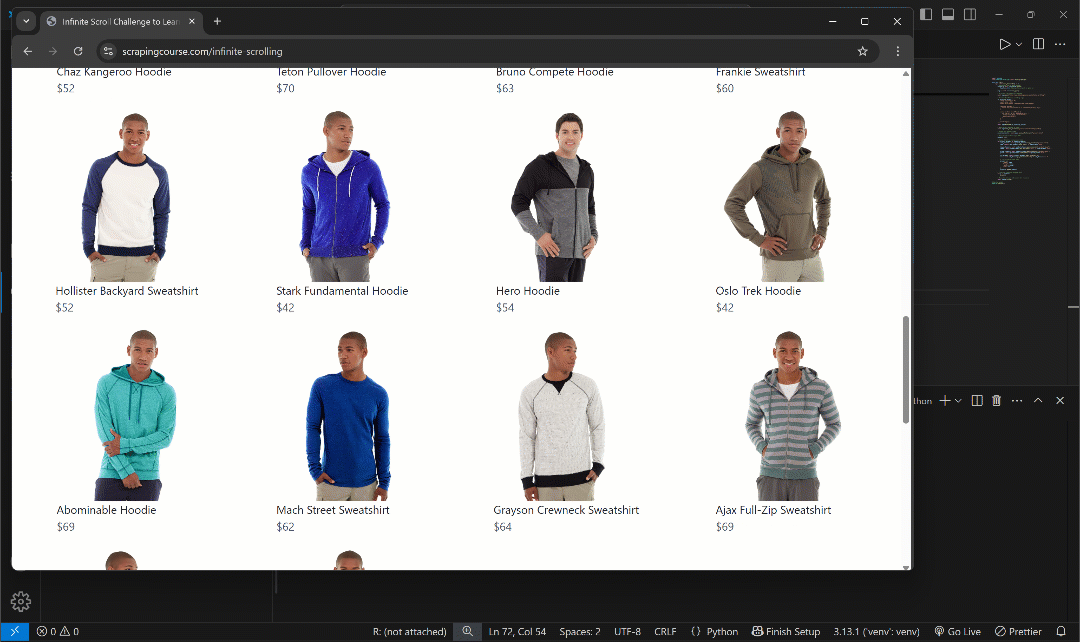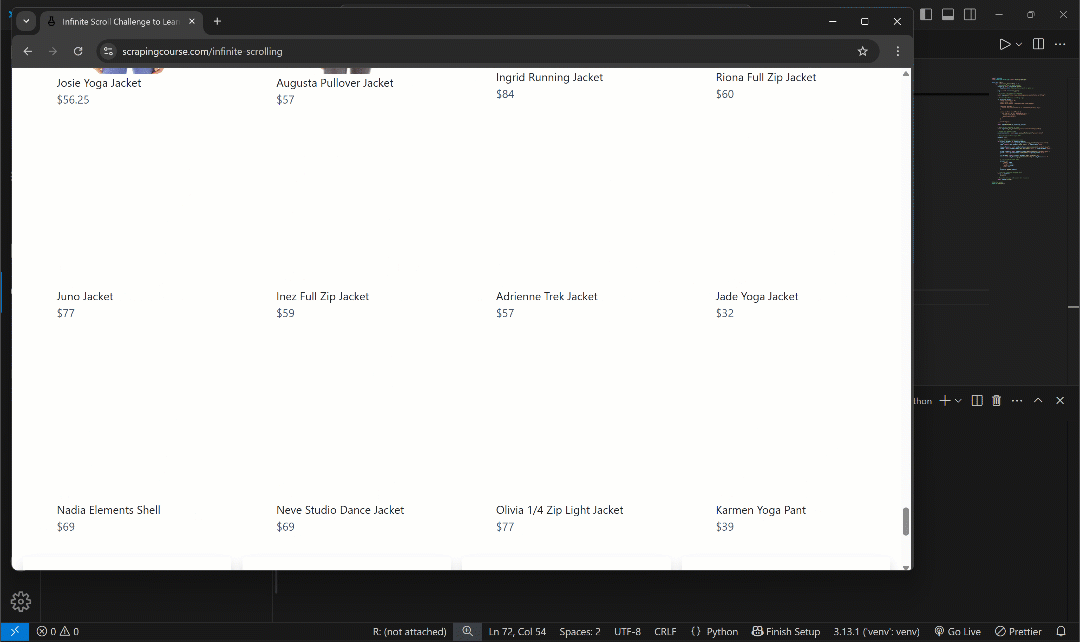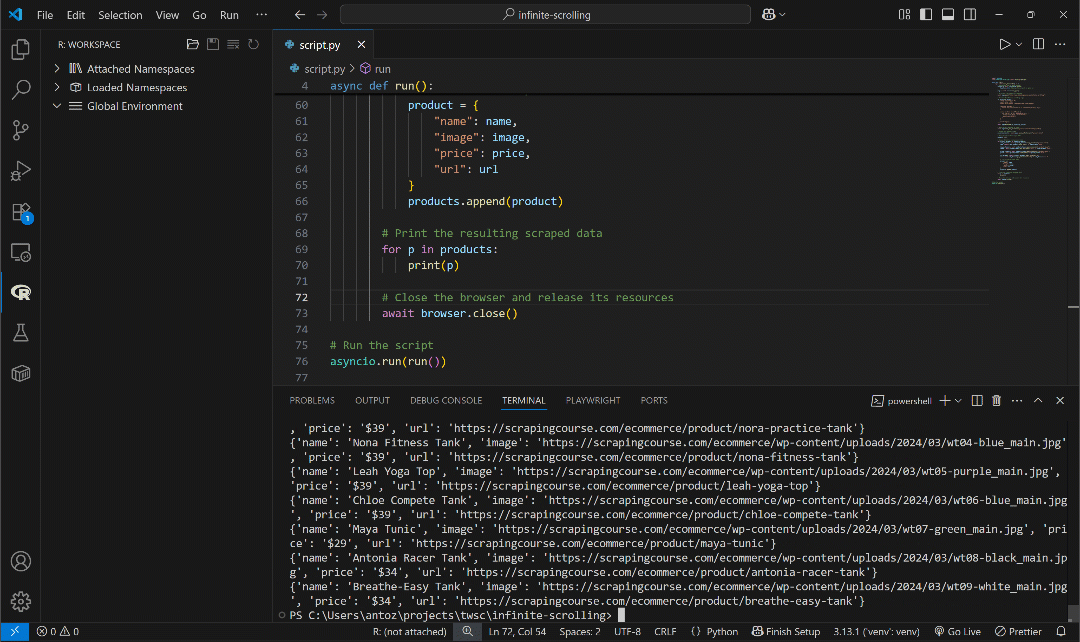
That’s what you should see when running the script:
The automated infinite scrolling scraping in action
As you can tell, the script:
Launches Chromium and visits the Infinite Scrolling page.
Executes the JavaScript scroll automation script on the page.
The output list contains many more than the original 12 products shown on the page initially. Actually, it includes all 186 products loaded on the page, which proves that the infinite scrolling browser automation worked successfully.
How to Deal with Infinite Scroll in Playwright, Puppeteer, and Selenium
What’s especially interesting in the interaction tutorial above are steps #2 and #3, where you execute the JavaScript scroll script and wait for the new products to load on the page.
Since you might prefer not to use Playwright or want to use other technologies, I’ll show you how to apply this logic in:
Puppeteer with JavaScript
Selenium with Python
Infinite Scrolling in Puppeteer (JavaScript)
const jsScrollScript = `
const maxScrolls = 20;
const delay = 500;
const scrollAmount = document.body.scrollHeight;
function wait(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function scrollPage() {
for (let i = 0; i < maxScrolls; i++) {
window.scrollBy(0, scrollAmount);
await wait(delay);
}
}
scrollPage();
`;
// inject and run the scroll script
await page.evaluate(jsScrollScript);
// wait for the 185th product to appear
await page.waitForSelector('.product-item:nth-of-type(185)', { timeout: 30000 });
Infinite Scrolling in Selenium (Python)
# Execute the JS scroll logic
js_scroll_script = """
const maxScrolls = 20;
const delay = 500;
const scrollAmount = document.body.scrollHeight;
function wait(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function scrollPage() {
for (let i = 0; i < maxScrolls; i++) {
window.scrollBy(0, scrollAmount);
await wait(delay);
}
}
return scrollPage();
"""
driver.execute_script(js_scroll_script)
# Wait for the 185th product to be present for up to 30 seconds
wait = WebDriverWait(driver, 30)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".product-item:nth-of-type(185)")))
Where the required imports are:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
The Web Scraping Club is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Conclusion
The goal of this post was to explain what infinite scrolling is, why replicating that interaction requires a browser automation tool, and why it can be so challenging to handle.
As shown in the step-by-step guide, with Playwright, you can deal with infinite scroll effectively with a couple of key steps. For completeness, I also demonstrated how to achieve the same result using Puppeteer and Selenium.
I hope you found this technical guide helpful and picked up something new along the way. Feel free to share your thoughts or experiences in the comments—until next time!