
Evolution from RAG to MCP: A Breakthrough for LLM Dynamic Knowledge Base
How to integrate real-time Google data into LLMs with the MCP server?

Large Language Models (LLMs) are the cornerstone technology in the field of Natural Language Processing (NLP), built on deep learning architectures like Transformer. These models possess the ability to understand and generate text at a near-human level. Code is the language of computers, while proteins and molecular sequences are the languages of biology—LLMs can be applied not only to linguistic interactions but also to scenarios requiring various forms of communication.
However, in today's market, countless large language models are locked in fierce competition. How can companies behind these LLMs refine their products to maintain cutting-edge capabilities and maximize market share on this battlefield?
Let’s uncover some reference solutions in this article!
The Evolution and Bottlenecks of LLMs
Powered by the Transformer architecture and vast amounts of pre-training data, Large Language Models (LLMs) have achieved breakthrough capabilities in text generation, multi-modal interaction, and more.
However, in the AI 3.0 era, their "static knowledge base" nature faces three critical challenges:
Lag in Real-Time Updates: The parameter-freezing mechanism means that knowledge becomes outdated after the training cutoff date, making it difficult to respond to time-sensitive events.
Domain Transfer Barriers: A single pre-trained corpus struggles to support cross-disciplinary knowledge integration, necessitating advancements in multi-source data alignment technologies.
System Integration Costs: Retrieval-Augmented Generation (RAG) involves complex subsystems like distributed vector databases and real-time index updates, posing significant engineering challenges.
Deep SerpApi 1.0
Deep SerpApi 1.0 is different from the traditional Google SERP API interface. It solves the limitations of large language models through 2 designs:
Continuously update information index through real-time data stream
Combine the latest network data with AI generation capabilities.
The platform has settled in AI agent workflow platforms such as Dify, which can automatically obtain real-time Google data and help users break through the timeliness limitations of traditional language models.
So, What is Deep SerpApi?

Deep SerpApi 1.0 is a dedicated search engine designed for large language models (LLMs) and AI agents. It provides real-time, accurate, and unbiased information, enabling AI applications to effectively retrieve and process data:
✅ It has built-in 15+ Google SERP scenario interfaces, extracting instant data easily and effectively. Here are 8 popular actors:

You can figure out more in Scrapeless Dashboard
Join our developer program and get 50K free calls per month!
✅ It covers 20+ data types, such as search results, news, videos, and images.
✅ It supports historical data updates within the past 24 hours.
Why choose Deep SerpApi?
Deep SerpApi has become a breakthrough tool in the field of dynamic data retrieval with its extremely low cost ($0.1-$0.3/1,000 queries) and 1-2 second response speed. It can also help traditional SEO companies and data analysis teams obtain Google SERP results at one twentieth of the price of traditional SERP API on the market.
LLM with Deep SerpApi: RAG is here
How does Deep SerpApi help LLM obtain the latest information and ensure accurate answers? Deep SerpApi is now available on Dify! Let's test whether Deep SerpApi can improve LLM's answering ability.
The following case uses Dify.ai and Deep SerpApi to build an SEO-friendly blog title generator:
Step 1. Create an app via "Create from Blank".
Select workflow and enter the name and description.

Step 2. Add input nodes and fields.

Step 3. Choose the Deep SerpApi node to help access Google.
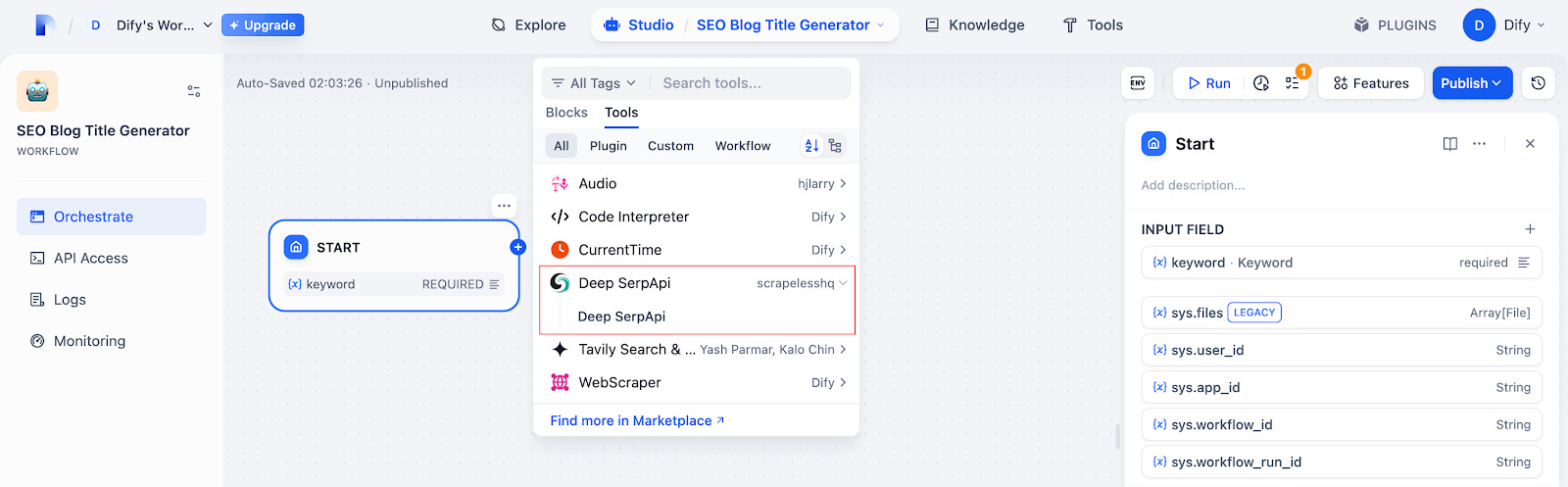
Set up search input.

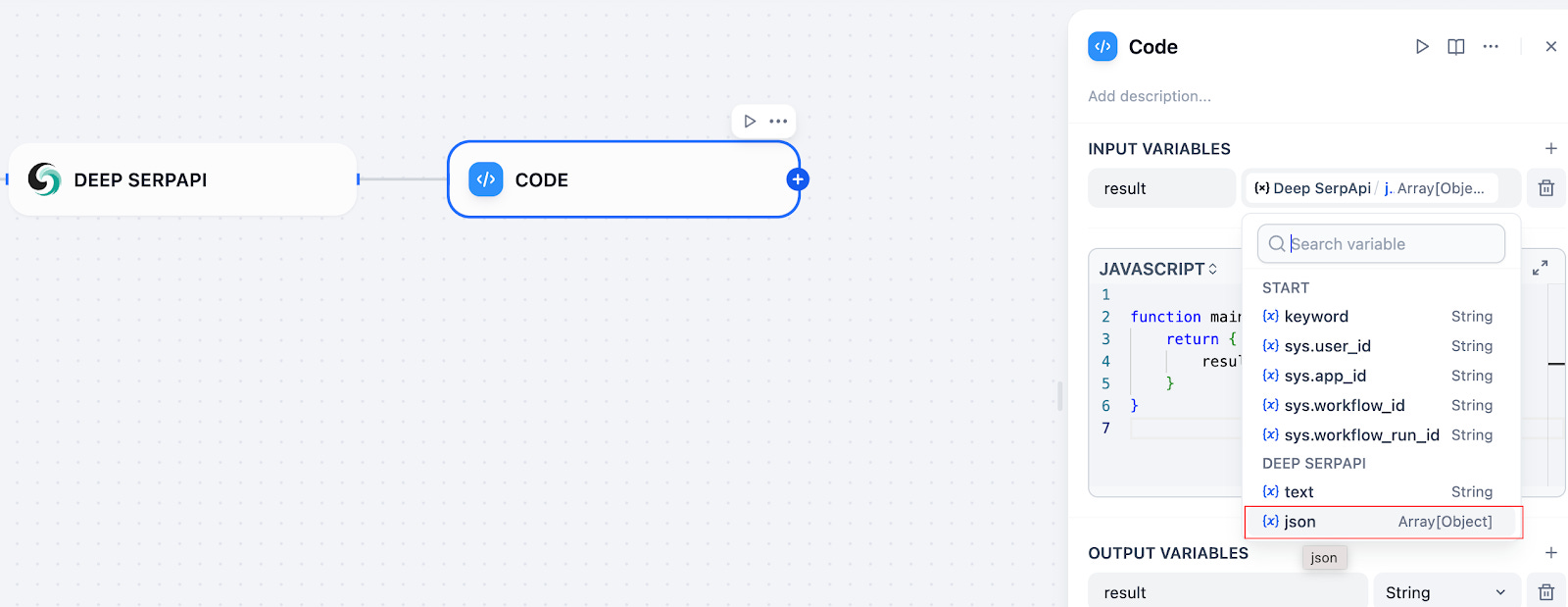
Step 4. Adapt data types. Since the output format of Deep SerpApi is JSON, we need to add a Code node to adapt the type:

Fill in the following code to convert the JSON structure into a string type for the parameter input of the next node:
function main({result}) {
return {
result: JSON.stringify(result)
}
}
Step 5. Summarize the results and generate blog titles.
Add an LLM node:
Select the gpt-3.5-turbo model (you can change to other LLM models at will), and fill in the following prompt words. The prompt words will use the search results of Deep SerpApi to generate a more friendly blog title:
SYSTEM:
You are an SEO expert and subject-matter expert. Your task is to generate an SEO article title for the keywords provided by the user based on the context of the Google Search.
USER:
For context about what my article should be about, these are the top ranking results for /keywords: /result
What are the principles that made these rank?
ASSISTANT:
To craft an SEO-friendly article title for the keywords "/keywords" that aligns with the principles observed in the top-ranking results you've shared, it's important to understand what made those titles effective. Here are the principles that likely contributed to their high rankings:
1. **Keywords Placement and Clarity**: Each title directly addresses the query by including the exact keywords or a very close variant. This clarity ensures search engines can easily understand the relevance of the content.
2. **Brevity and Directness**: The titles are concise, making them easy to read and understand quickly. They avoid unnecessary words and get straight to the point.
3. **Inclusion of Definitions or Explanations**: The titles suggest that the article will define or explain the concept, which is precisely what someone searching for "/keywords" would be looking for.
4. **Variety in Presentation**: Despite covering similar content, each title approaches the subject from a slightly different angle. This variety can capture interest from a broader audience.
USER:
Given these principles, please help me generate a title that will rank for the keywords "/keywords" by modeling after the syntax of the top ranking titles. Don't copy but give me something better, and avoid language such as "Master", "Comprehensive" or "Discover" or "Unveil". Do not use gerunds, and write in active, present voice only. Return the title only. Do not include any special symbols such as quotation mark and colons.

Step 6. Add output result node.

Congratulation! The core process is now complete, next let's test it!
Step 7. Trial run
Input the keywords "AI content generation" and click "Start Run".

We can see that a blog title with a high Google ranking has been successfully generated.

Step 8. Release and use
If the above steps are completed, you can confidently proceed with the release.

Once the release is complete, we can use the application:

However, the RAG has three major technical boundaries
Real-time bottleneck: relying on batch data capture, unable to handle millisecond-level real-time interactions (such as stock trading)
Interface fragmentation: 20+ API keys need to be managed independently, and the development and maintenance cost exceeds $5/thousand queries
Security isolation restrictions: data cleaning/vectorization needs to be deployed locally, which makes it difficult to meet compliance requirements such as GDPR
How to avoid RAG traps has become the biggest technical challenge for many large language models and Deep SerpApi.
MCP: the inevitable choice for the AI Agent ecosystem
Model Context Protocol (MCP) released by Claude (Anthropic). This open protocol was officially launched in November 2024, aiming to achieve seamless integration of large language models (LLM) with external data sources and tools through standardized interfaces.
Anthropic developed MCP to address LLMs' "data silo" problem: traditional RAG systems require developing custom interfaces for each data source, with development costs exceeding $5 per thousand queries.
Why MCP is the Future?

Core Features
Standardized Protocol. MCP serves as the "USB-C interface" for AI applications, replacing fragmented Agent code integration with a unified protocol. Developers can rapidly connect to 20+ data sources (e.g., GitHub, Slack, Google SERP) through a single interface – enabling simultaneous local file access and remote API calls.
Secure Architecture. Adopts a client-server model where all data processing occurs locally, preventing sensitive information from cloud exposure. Servers only expose controlled functions (e.g., read-only access to specific folders) with federated learning risk-control models filtering abnormal data.
Ecosystem Scalability. Supports dynamic knowledge injection and multi-server collaboration, including:
Finance: Real-time SEC filings and Bloomberg Terminal integration
Development: Automated database queries with code generation
Enterprise: Internal system orchestration for workflow automation
How to Enhance AI Capabilities with MCP?
Currently, MCP has been deeply integrated into IDEs like Cursor and Windsurf, supporting scenarios such as automated PR creation and real-time data querying. Developers have hailed it as a "10x productivity booster." Future plans include expanding to remote deployments and enabling access for more mainstream models.
Through relentless research, the Scrapeless team has overcome technical barriers and officially launched the Google SERP All-in-One MCP Enhanced API. Additionally, updates will continue to adapt MCP servers for more scenarios and features.
How to Use Scrapeless MCP Server in AI Programs?
Below, we’ll walk you through tutorials for using Claude, Cursor, and Cline.
⚠️ Prerequisites
Ensure you have Node.js and npm installed. If not, visit the Node.js website to download them.
Log in to Scrapeless and obtain your API token.

1️⃣ Using Scrapeless MCP server on Claude
Step 1. Open your terminal and enter the following command:
vim ~/Library/Application\ Support/Claude/claude_desktop_config.json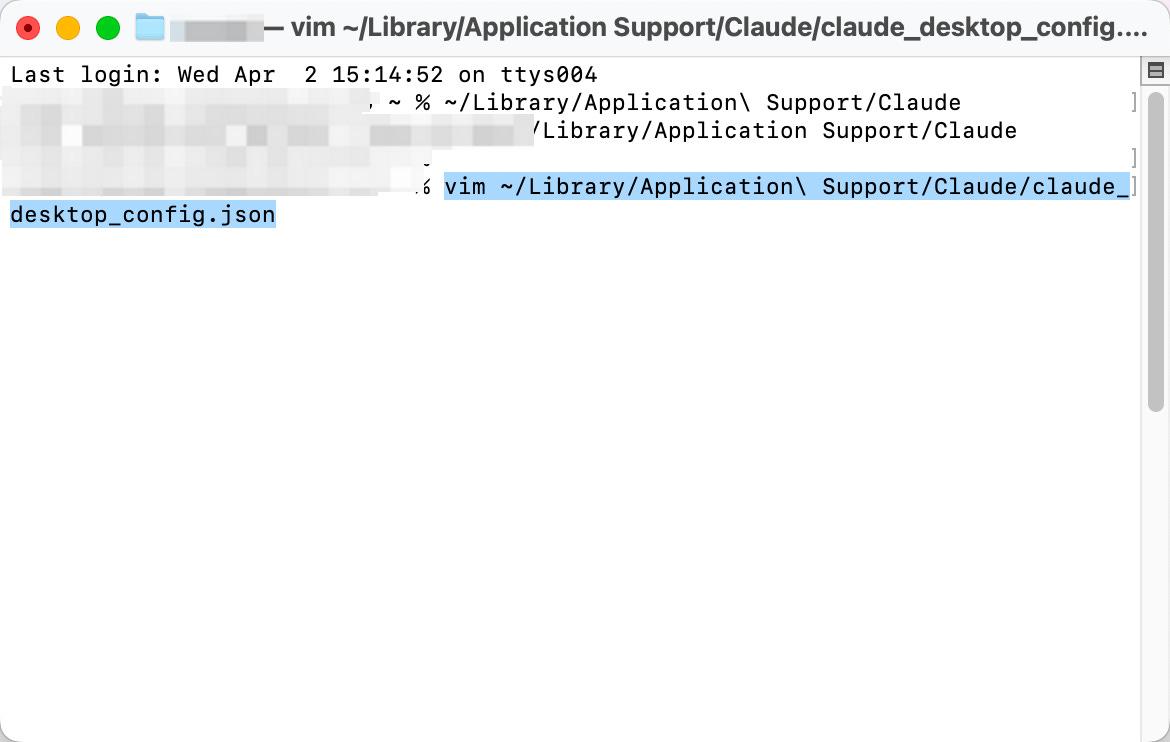
After pressing Enter, you should see the following result:

Step 2. Use the following code to connect to Scrapeless MCP:
You can also visit our Scrapeless MCP Server Tutorial Documentation for more details.
{
"mcpServers": {
"scrapelessMcpServer": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY" // replace with your API key
}
}
}
Paste the code and save it by typing :, then x, and finally press Enter.

Step 3. Open Claude. When you see a hammer icon, it means the MCP server is successfully connected! Now Claude can invoke MCP.

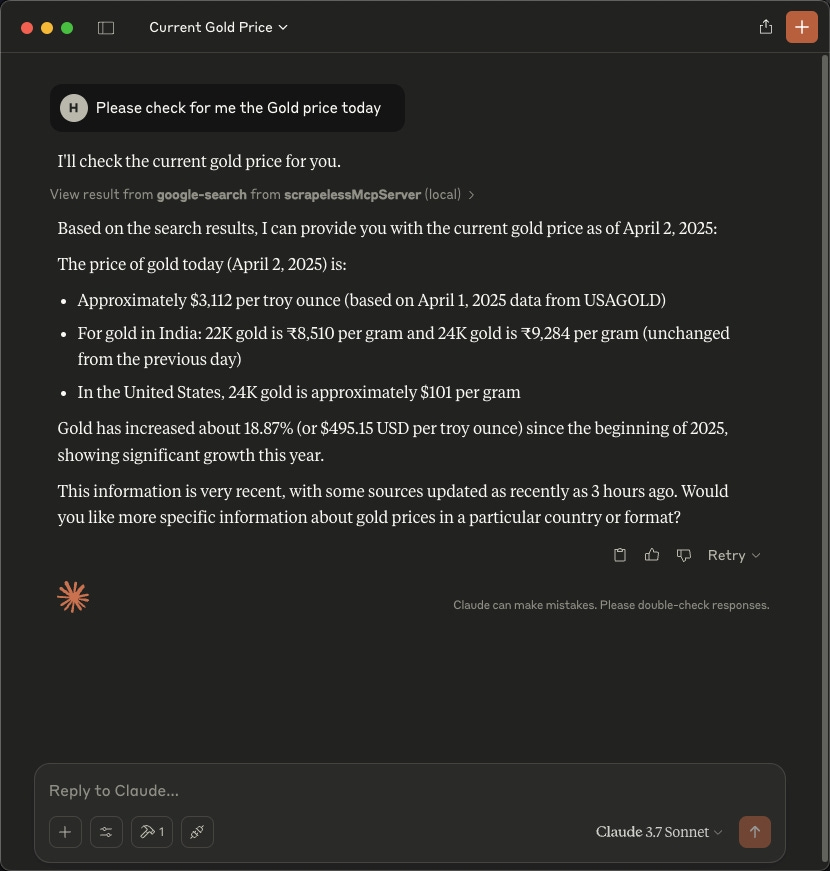
Input your query, e.g., "Please check for me the Gold price today."
Allow Claude to invoke the Scrapeless MCP server.

Get the response.
2️⃣ Using Scrapeless MCP server on Cursor
Step 1. Configure Scrapeless in Cursor
Click Settings, then find the "MCP" option in the left-hand menu.
Click Add new global MCP server to open the configuration box.

Configure Scrapeless
Just like with Claude, paste the configuration code into the program box:
{
"mcpServers": {
"scrapelessMcpServer": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY" // replace with your API key
}
}
}
}

Step 2. Use Cursor
Now that you've successfully configured the Scrapeless MCP Server, simply input commands in the dialogue box to invoke Scrapeless for information. For example, ask, Please help me check today's gold price. You’ll see that Cursor has successfully invoked the Scrapeless MCP Server and returned the correct answer.

Additional Resource: How to connect Scrapeless on Cline?
The Bottom Lines
In the AI 3.0 era, data interface protocols have evolved from "technical options" to "strategic infrastructure." Deep SerpApi solidifies its current advantages with RAG technology while expanding future horizons with the MCP protocol.
Through the dual-engine architecture of RAG + MCP, the paradigm for enterprise AI application development is being redefined:
Technological Democratization: Reduce development costs from $5/1,000 queries to $0.1, making real-time intelligent APIs affordable for small and medium-sized enterprises
Ecosystem Aggregation Effect: As one of the first certified service providers of the MCP protocol, seamless integration with mainstream models like Cline, Cursor, and Claude Desktop has been achieved.
Security and Compliance Benchmark: Built-in federated learning risk control models ensure cross-border data transmission complies with regulations like GDPR and CCPA.
Looking for APIs for other scenarios? Scrapeless’s social media and e-commerce APIs (e.g., Amazon, Shopee, Walmart, TikTok) make data acquisition even simpler.
 | A guest post by
|