
The Lab #46: Fingerprint injection in Playwright
A home-made solution to bypass anti-bots by changing your browser fingerprint.

In the past articles of The Lab, and especially when we talked about bypassing Cloudflare, we have seen commercial solutions like anti-detect browsers for generating a consistent fingerprint able to bypass anti-bots solutions.

I didn’t find any OSS solution to achieve similar results (in Python) unless I encountered this repository, Browserforge, which is a reimplementation of Apify's fingerprint suite in Python.
Of course, I needed to test it!
Anti-ban solutions: Buy versus Make
While until some years ago, a good setup for your Scrapy or Selenium scraper was good enough to overcome anti-bot solutions, I think you already know that today this is not true anymore.
We have companies pouring money and time into anti-bot solutions more and more hard to overcome and raising the bar for having a 100% success rate when scraping.
There’s a list of challenges today that a professional web scraper needs to face:
IP ban
Rate limiting on requests
Browser fingerprinting
WebRTC leak
TLS Fingerprinting
and for sure I’ve forgotten something else.
This means that building your scrapers to overcome anti-bots requires adding more and more tools:
Proxies (from residential to mobile)
Rotating IPs
Anti-detect browsers
Browser automation tools
In the Discord Server of The Web Scraping Club, we often talk about Make vs Buy and it’s an interesting debate that has a right and wrong answer.
My two cents on this topic are that when competing against anti-bot vendors, you’re against companies with R&D labs and many talented engineers working on detecting bots. Is this a race you want to participate in it?
If you have a passion for anti-bot evasion techniques, deobfuscation, and maybe you’re focused on a few websites, it could be worth it for you. I love to test new tools and find new creative solutions for these challenges, so I completely understand this. You learn a lot and grow as a scraping professional, by tackling challenges in first person.
On the other hand, from a business perspective, if you run a company based on web data or you’re a data vendor, you surely have deadlines to meet and these rarely give you the time to dig deep on reverse engineering anti-bots. Your mission is to deliver data (or services based on that), not to bypass CAPTCHAs. In this case, you would prefer a commercial solution that is easy to implement and reliable, which hopefully you could charge to your final customers.
My experience leads me to a different approach: Buy AND Make. To deliver data timely while preserving the balance sheet of the company by avoiding overspending on commercial solutions, I’ve adopted a mind map of challenges I could tackle with OSS tools and others with commercial ones.
It’s a matter of finding the balance between budget and time and this is variable for every company.
All this intro is just to say that one of the challenges I delegate to commercial tools is browser fingerprinting: whenever I encounter a website that heavily relies on browser fingerprinting to block my scrapers, I use commercial tools like unblockers or anti-detect browsers to overcome them.
Today, since I’ve discovered Browserforge, which can be used together with Playwright, I’m testing this OSS solution to check if I can get the same results as a commercial one like Kameleo against three well-known anti-bot solutions.
Before continuing, a quick reminder about ScrapeCon 2024 by Bright Data, is on the 2nd of April.
Expect hands-on sessions, live coding, expert Q&As, and insights from the industry's top practitioners and tech leaders.
You cannot miss this conference if you want to know more about the world of web data collection and learn new skills and strategies to optimize your scraping operations.

Setting the baseline with Playwright
The test consists of loading a first check-up page of your browser fingerprint and then two pages from the Harrods.com website, protected by Cloudflare, the Footlocker website protected by Datadome, and the StockX website protected by PerimeterX. We’re running these tests from an AWS server and using residential proxies to avoid blocks because of the IP.
All the code of the tests can be found in The Lab GitHub repository, available for paying users, under folder 46.Fingerprint-Injection.
If you already subscribed but don’t have access to the repository, please write me at pier@thewebscraping.club since I need to add you manually.
First run: test with Chromium with default parameters
The first run we’ll do is using a basic Chromium Browser window to take the Browsernet test and check its results. In the following series of screenshots, we’ll see the issues detected.


First of all, a proxy is detected because of the WebRTC IP address leak. Every browser has embedded a WebRTC client and this technology allows real-time communication between browsers without requiring an intermediate server
WebRTC leaks take place when you’re trying to establish video or audio communication with another person via a browser that uses WebRTC technology, revealing your real IP even if you’re behind a proxy.

Another issue here is the timestamp obtained by querying the browser’s API and the one deducted by the timezone of the IP. If they’re different, it’s another sign you’re using a proxy.

Last but not least, we have the SwiftShader renderer. As mentioned in the documentation, it is a high-performance CPU-based implementation of the Vulkan 1.3 graphics API. This means that it’s used mainly by devices with no GPU available, like servers in a data center. This is one of the main red flags used for discriminating between bots and humans, as we’ve seen in previous articles of The Lab.
Second run: test with Chromium with Firefox on Windows fingerprint
Now we’ll inject a fingerprint using Browserforge and repeat the tests. I decided to use a Chromium browser but inject a fingerprint of Firefox on a Windows machine, let’s see what happens.
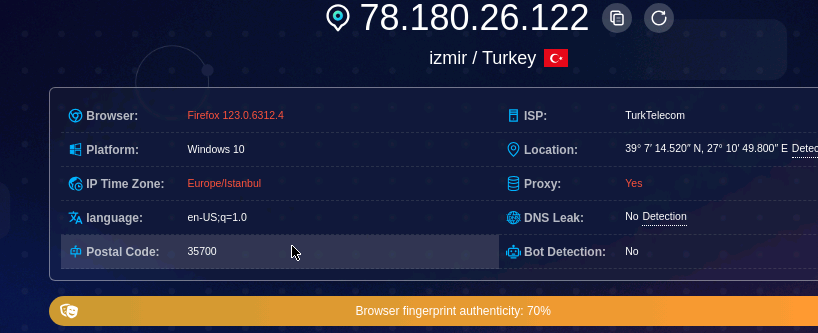
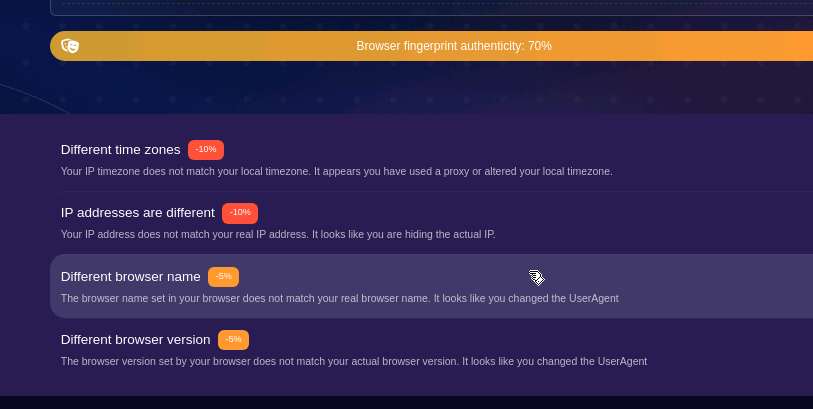
As I suspected, using a different browser for generating the fingerprint created some issues. The headers of the browser (Chromium) did not match the browser in the fingerprint (Firefox), and the test recognized it, while it correctly noted that we were faking a Windows 10 machine.

The timezone was wrong because the system time did not match the timezone of the IP.
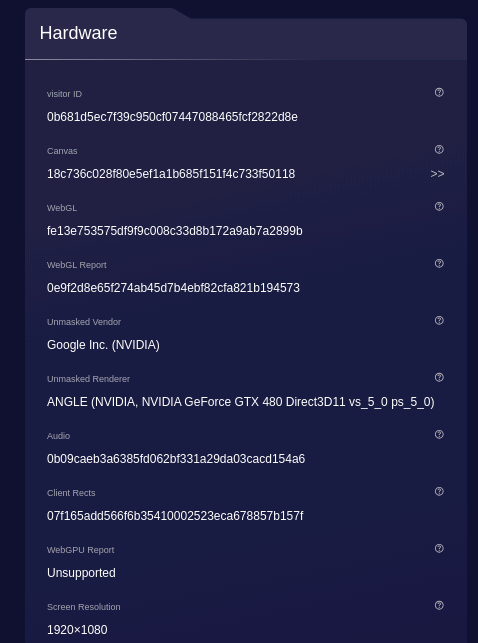
A good news, instead was the detection of the Nvidia GeForce graphic card.
Third run: test with Firefox Browser with Firefox on Windows fingerprint
I’ve made some adjustments for the third test: since the AWS machine is in the Berlin data center, I’ve restricted the IPs only to Germany. I’ve also made a change on the system timezone of the machine, to set it correctly to the German time.
Using a Firefox browser with a Firefox Fingerprint injected, together with these adjustments, the test improved.

We still get the proxy detected because of WebRTC, but at least the IP timezone is correct.
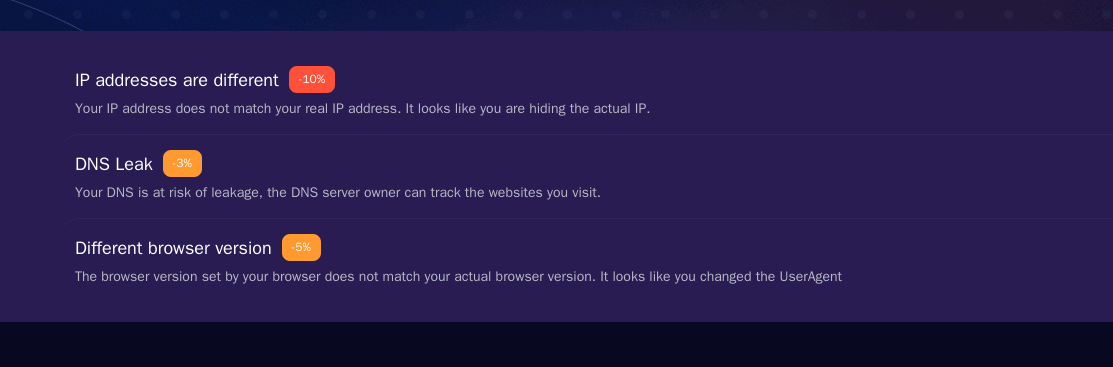
The only thing is that we cannot select the version of Firefox to be fingerprinted, and this creates a discrepancy between the Firefox version used in Playwright and the one used for the fingerprint.
A comparison run with Kameleo
We obtained a good fingerprint spoofing but not perfect. But how far we’re from a commercial solution like Kameleo?
On the Kameleo profile, after disabling manually the WebRTC (which is something that can’t be done programmatically in traditional browsers) and setting the right timezone, here’s the result.
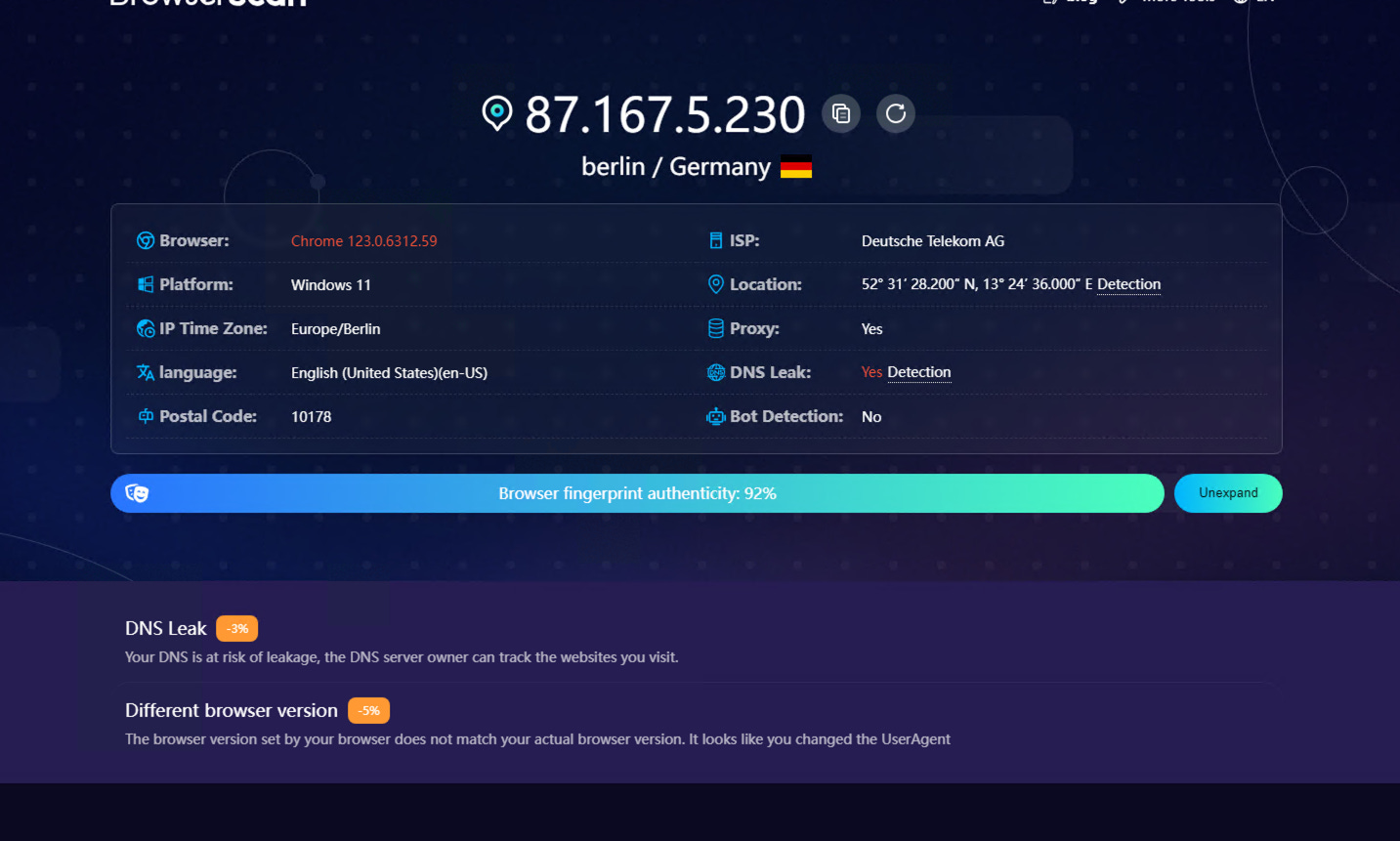
A much more coherent fingerprint with only a small issue of the version of the browser.
Fingerprint injection implementation and tests against anti-bots
Given the fact that with a commercial anti-detect browser we have a better and more coherent browser fingerprint, is our homemade solution enough to bypass anti-bots?
Let’s start by implementing it in our scraper.
