When scraping the web, we face several challenges due to anti-bot systems trying to block automated access. In this scenario, proxies are an essential tool to overcome a lot of difficulties.
This article provides an overview of the proxy landscape. Then, it explores two key proxy types: residential and mobile. We will compare them and understand their strengths to help you choose effectively between them, based on your specific use case.
Let’s dive in!
Before proceeding, let me thank NetNut, the platinum partner of the month. They have prepared a juicy offer for you: up to 1 TB of web unblocker for free.
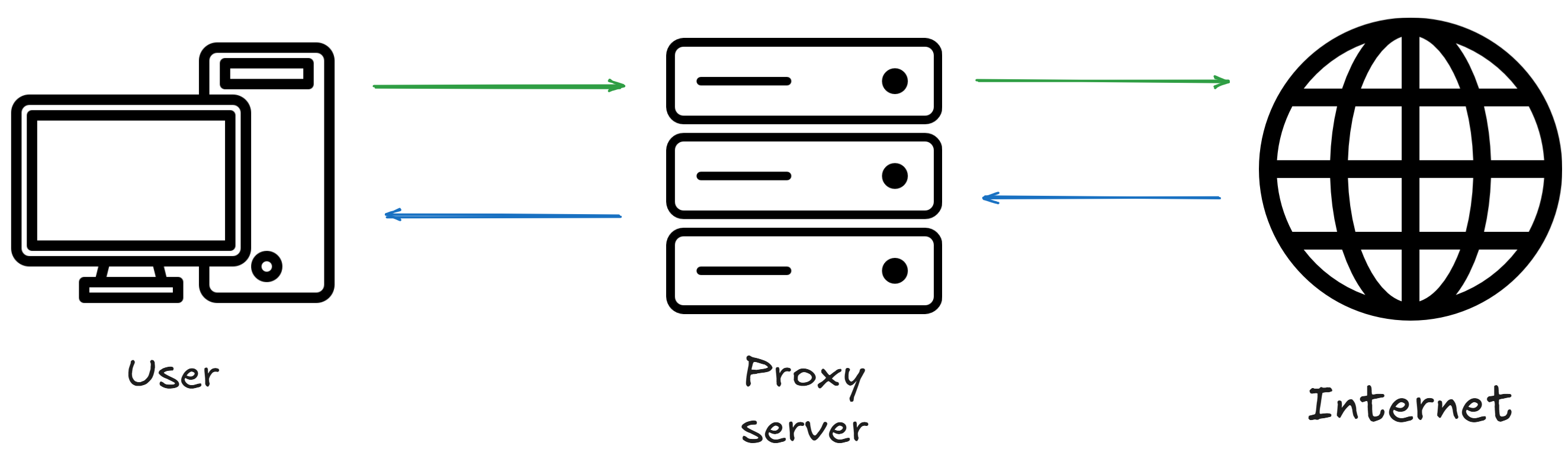
A proxy is a server that acts as an intermediary between the user and the network on the Internet. Think of it as a middleman that manages requests and responses between the parties:
In web scraping, a proxy handles your scraper's data requests. This means your scraper doesn't contact the data source directly. This way, the website sees the proxy's IP, not yours. This is why proxies are indispensable in web scraping. They enable you to:
Mask your IP address: This is important for anonymity and avoiding IP-based blocks.
Bypass geo-restrictions: Access content limited to specific geographic regions by using a proxy located in that region.
Distribute requests: Make numerous requests without overwhelming a single IP. This makes the traffic appear more organic-like to anti-bot systems.
Manage rate limits: Avoid triggering rate-limiting mechanisms by rotating through a pool of different IPs.
Without proxies, large-scale or continuous web scraping against any reasonably protected target is simply not possible.
This episode is brought to you by our Gold Partners. Be sure to have a look at the Club Deals page to discover their generous offers available for the TWSC readers.
Understanding the Proxy Landscape
Proxies can be categorized in several operational characteristics, including their underlying communication protocols, visibility to target servers, the origin of their IP addresses, and IP behavior patterns.
Let’s discuss them.
Protocol-Based Distinctions
Proxy servers interface with web protocols in distinct ways:
HTTP proxies are engineered to handle Hypertext Transfer Protocol traffic. They are widely accessible and often cost-effective. However, their utility is generally confined to basic web navigation or accessing resources where security is not paramount.
HTTPS proxies incorporate an SSL/TLS encryption layer between the client device and the proxy server. This enhancement, with respect to HTTP ones, provides a more secure channel. This makes them suitable for interactions requiring logins or the transmission of sensitive data. However, the cryptographic overhead may introduce marginal latency.
SOCKS proxies—particularly the SOCKS5 iteration—offer a more versatile, protocol-agnostic approach. They can manage diverse traffic types over TCP or UDP. This extends their applicability beyond standard web browsing to areas like P2P networking, online gaming, or specialized software requiring non-HTTP internet access. SOCKS5 also provides more robust security features compared to HTTP/HTTPS proxies. However, their configuration can be more intricate, and performance may vary.
The degree to which a proxy reveals its nature and the client's original IP address defines its visibility:
Transparent proxies don’t obfuscate the client's IP. So, they provide no client-side privacy. Their utility lies in network administration, such as content filtering within organizational networks (e.g., educational institutions or corporate environments), enforcing access controls, or implementing network-level caching to optimize web access for multiple users.
Anonymous proxies represent a step up, concealing the client's true IP address. However, they typically identify themselves as proxy servers in the HTTP headers of the requests they forward. This provides a basic level of IP masking suitable for casual browsing or circumventing rudimentary geo-restrictions. However, target systems can still detect them and potentially restrict access based on the proxy's self-identification.
High anonymity proxies (often known as elite proxies) offer the most robust privacy. They mask the client's IP address and do not reveal their status as a proxy intermediary in the request headers. This makes it more challenging for target servers to detect their use. For this reason, they are preferable for activities demanding strong anonymity and the circumvention of more sophisticated detection mechanisms. Obviously, reliable high-anonymity proxies generally have high costs.
IP Behavior Patterns
How IP addresses are assigned and managed further differentiates proxy services:
Static proxies provide the client with one or more IP addresses that remain constant over time. This consistency is useful for scenarios requiring a stable identity, such as managing specific online accounts that benefit from consistent login IPs or accessing services that use IP whitelisting. The primary vulnerability is that if a static IP is compromised or blocked, it becomes unusable, and prolonged use of a single IP can diminish anonymity.
Rotating proxies automatically cycle through a pool of IP addresses, changing the output IP at predefined intervals or with each new request. This dynamic allocation enhances anonymity and is highly effective for large-scale web scraping. The main challenge with rotating proxies lies in maintaining session persistence when required by the target application.
Dedicated proxies offer IP addresses for the exclusive use of a single client. This ensures that the client has complete control over the IP's usage history and reputation, which is critical for activities like managing high-value accounts or email marketing campaigns where IP reputation directly impacts deliverability. Dedicated IPs generally provide better performance and reliability as resources are not shared, but they are typically expensive, and the client sustains the full impact if their dedicated IP is blacklisted.
Shared proxies involve multiple clients simultaneously utilizing the same pool of IP addresses. This model reduces costs but introduces risks, as the actions of one user can negatively affect the IP's reputation for all other users sharing it. Consequently, shared proxies are generally suitable for low-budget tasks where IP reputation is less critical and occasional disruptions are tolerable. Performance and reliability can also be compromised due to the shared nature of the resources.
IP Address Origin
Here we arrive at the core of our interest for this article. The origin of a proxy's IP address is a critical factor of its perceived legitimacy and, consequently, its effectiveness against anti-bot systems:
Datacenter proxies utilize IP addresses assigned to servers located within data centers. As their IPs originate from commercially registered blocks, this makes them readily identifiable and frequently blacklisted by anti-bot systems.
Residential proxies employ IP addresses assigned by Internet Service Providers (ISPs) to genuine residential households. This grants them a higher trust score than datacenter ones, as their traffic patterns appear to originate from legitimate end-users.
ISP proxies (Static Residential Proxies) represent a hybrid category. It utilizes static IP addresses assigned by ISPs but is often hosted on servers within data centers. The objective is to combine the high reputation associated with ISP-assigned addresses with the performance and stability of datacenter infrastructure.
Mobile proxies route traffic through IP addresses that Mobile Network Operators (MNOs) assign to mobile devices on cellular networks (e.g., 3G, 4G, 5G). Among the categories discussed, mobile IPs earn an exceptionally high trust score, making them the most trusted. This is partly because MNOs frequently use Carrier-Grade NAT (CGNAT). This technology lets many different mobile users share a single public IP address, mainly to conserve limited IPv4 addresses. Consequently, external websites see traffic from numerous mobile devices as if it comes from this single IP. While it might seem strange that an IP many users share (where one could misbehave) has such a high trust score, services hesitate to block it, as this would inadvertently affect many innocent users.
Before continuing with the article, I wanted to let you know that I've started my community in Circle. It’s a place where we can share our experiences and knowledge, and it’s included in your subscription. Give it a try at this link.
Head-to-Head: Residential vs. Mobile Proxies for Evasion
Before discussing the comparison between residential and mobile proxies, let’s define the evaluation criteria we’ll use:
IP trust score: This metric quantifies how target web servers and their associated anti-bot systems perceive an IP address's legitimacy. An IP address with a high trust score is less likely to trigger scrutiny, challenges (like CAPTCHAs), or outright blocks from these systems. Factors such as the IP's origin, its historical activity, and whether known blacklists list the IP, influence this score.
Anonymity level: This defines how well a proxy hides the client's real IP address and location. It also refers to how well the proxy hides its own use. When anonymity is high, target systems find it harder to trace activity back to the scraping setup. It also becomes more difficult for them to even realize that a proxy is handling the traffic.
IP pool size and diversity: This refers to how many unique IP addresses the proxy network offers and where those IPs are located (like in different countries, cities, or with various internet providers). When the network has a large and varied selection of IPs, users can change their IP addresses more effectively. They can also target specific geographic locations more precisely. This also means they are less likely to run out of usable IPs when trying to access a particular website.
Speed (throughput and latency): This metric measures the data transfer rate (throughput) and the delay in data transmission (latency) introduced by the proxy. High latency or low throughput can significantly impede the efficiency of data extraction operations, especially at scale.
Reliability (connection stability and IP availability): Reliability describes how consistently the proxy connection works and how often individual IPs in the pool are active. If proxies are unreliable, connections might drop often, requests might fail, and users will need to build more complicated systems to handle errors and retry requests.
Cost: This refers to the financial expenses associated with buying and utilizing the proxy service. Costs can vary based on proxy type, pool size, features, and provider.
Now that we have the metrics, let's compare how well residential and mobile proxies bypass anti-bot systems:
IP trust score:
Mobile proxies: These are generally the best. Anti-bot systems are very hesitant to block mobile carrier IPs because these IPs inherently have more trust. This is particularly due to CGNAT.
Residential proxies: These have a high trust score, much higher than datacenter IPs. However, if an anti-bot system flags a specific residential IP for suspicious activity, it's more likely to block that IP compared to a mobile IP.
Anonymity level:
Mobile: These are slightly better than residential. In particular, the use of CGNAT adds an extra, built-in layer of disguise, making it harder to single out what one specific user is doing.
Residential: These offer excellent anonymity. Typically, a residential IP address links to a single household's internet connection at any one time.
IP Pool size and diversity:
Mobile: While the number of available mobile IPs is growing, the selection can sometimes be more limited. This is especially true if you need IPs from very specific geographic locations or from particular mobile carriers.
Residential: These often have an advantage. Companies that provide residential proxies frequently control larger IP pools. These pools also offer more specific geographic targeting, covering many countries, cities, and internet service providers.
Speed:
Mobile: The performance of these proxies naturally varies more. It depends on things like the strength of the cell signal, how busy the local network is, and the quality of the mobile carrier's equipment.
Residential: These can perform more consistently if the device sharing its internet connection has a stable, fast connection. However, because these networks rely on individual users' connections (peer-to-peer), performance can vary.
Reliability:
Mobile: Individual mobile IPs might change more often due to how mobile networks operate (for instance, when a device reconnects or gets a new IP lease). However, the proxy provider can engineer the connection through the mobile network for high stability. So, the mobile IP type is inherently reliable because systems are less likely to block it.
Residential: A specific residential IP might be less stable because it depends on whether the end-user's device is online. However, well-managed residential proxy networks address this by quickly switching to other available IPs from their large pools.
Cost:
Mobile: These cost considerably more. This higher price reflects the greater expenses for infrastructure, such as SIM cards, mobile data plans, and specialized hardware.
Residential: These are more budget-friendly. It generally costs less to get and run residential proxies compared to mobile proxies.
Do you want a better overview of how much proxies cost per provider? Take a look at our Proxy Pricing Benchmark Tool!
Guiding Your Proxy Selection for Effective Anti-Bot Evasion
To make the optimal choice between residential and mobile proxies for your anti-bot evasion strategy, consider the following factors:
Evaluate target sophistication:
Choose mobile proxies for sites with strong anti-bot systems like banking, limited-edition product drops, airline ticketing, or similar cases. This is key if they aggressively detect non-mobile devices or quickly block residential proxies.
Use residential proxies for e-commerce, social media, travel sites, or similar cases with moderate anti-bot measures, especially if they don't heavily fingerprint non-mobile devices.
Prioritize mobile proxies if the target mainly serves mobile users, requiring your traffic to look like it's from a mobile device. Also, use them for mobile app APIs that strictly check traffic authenticity.
Balance budget and data value:
Mobile proxies cost more. Select them when the data has high value and the need for top success rates justifies the expense.
If your budget is tight, consider high-quality residential proxies, as long as they can bypass the target's anti-bot systems.
Consider scale and geo-targeting:
For large-scale scraping, residential proxies might offer a better cost-to-volume ratio if they are effective enough.
If you need many diverse IPs or IPs from specific locations, check which proxy type your provider offers with better coverage. Residential proxies often have more granular geo-targeting.
Determine session needs:
If you need long sessions with the same IP, discuss this with proxy providers. Both residential and mobile proxies can offer solutions, but their methods for session persistence differ. In particular, residential proxies often achieve session persistence by assigning a specific, relatively stable home internet IP for a period, while mobile proxies manage it by maintaining a connection through a particular mobile device or SIM card, which is inherently more dynamic.
Evaluating Mobile and Residential Proxies: A Practical Approach
The difference between mobile and residential proxies can also be evaluated in practice. Let’s go through an example of IP fraud comparison and how you can implement a solution that uses proxies in Python.
Checking IP Fraud Score
You can verify the fraud level of the IP using an online service like Scamalytics. For this test, I picked one residential and one mobile proxy IP from the same provider.
Here is the result I got with the residential proxy:
This IP is classified as very risky. This increases the chances of getting blocked when web scraping. Among the other results you get from the IP fraud service, an interesting one on the same IP is the following:
The IP fraud checker is not sure whether this residential IP can come from a data center or not. This result is important compared to the upcoming analysis on a mobile proxy.
So, let’s verify the IP fraud level on the mobile proxy:
Here we are! The IP fraud score of this mobile proxy is classified as low. This increases the possibility of not being blocked when scraping the web.
Now, let’s see if this can be localized in a datacenter or not:
There you go! Another proof that this mobile proxy is a high-quality one.
Another practical way to differentiate proxies is by implementing a script. Suppose you have to create a large scraper on a target website with high anti-bot systems. Suppose you also want to see if a residential proxy can be more effective than a mobile one, so that you can get the idea of the economical investment you need—you may need more than just one, for example (also, pricing plans are flexible. A lot of providers allow you to pay as you go, for example). The idea could be to develop a script that gets a sequential response from the target page:
Without any proxy.
With the residential proxy.
With the mobile proxy.
To do so, you have to first retrieve at least a mobile and a residential proxy from a provider of your choice. Then, install requests:
pip install requests
Now, you can write a Python script as follows:
import requests
def test_connection(url, proxy_type=None, proxy_address=None):
proxies = None
if proxy_address:
proxies = {
"http": f"http://{proxy_address}",
"https": f"http://{proxy_address}",
}
try:
response = requests.get(url, proxies=proxies, timeout=10)
if response.status_code == 200:
print(f"{proxy_type or 'No'} proxy succeeded: {response.status_code}")
else:
print(f"{proxy_type or 'No'} proxy failed: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"{proxy_type or 'No'} proxy error: {e}")
# URL to test
url = "<https://example.com>" # Change with your target URL
# Proxy addresses
residential_proxy = "<residential proxy>" # Change with your residential proxy
mobile_proxy = "<mobile proxy>" # Change with your mobile proxy
# Test without proxies
test_connection(url)
# Test with residential and mobile proxies
test_connection(url, "Residential", residential_proxy)
test_connection(url, "Mobile", mobile_proxy)
Suppose you named your file scraper.py, launch it with:
python scraper.py
The expected result should be similar to the following:
No proxy error: HTTPSConnectionPool(host='www.example.com', port=443): Read timed out. (read timeout=10)
Residential proxy failed: 4xx/5xx
Mobile proxy succeded: 200
The expected result can be interpreted as follows:
The request without any proxy got a runtime error. This means that, during the 10 seconds of timeout, it was not able to succeed with the request. No real error here: you can adjust the timeout as you prefer and see how the result changes, but you should expect an error.
The request with the residential proxy failed with a 4xx or 5xx error. This means that the server blocked or denied the request. Generally, 403 is the most common error you can get.
The request with the mobile proxy succeeded with a 200 code. Hooray! You got the response when scraping the target website.
If you want to try this code, you need to find a suitable target website. Use the information in the section “Guiding Your Proxy Selection for Effective Anti-Bot Evasion” to test suitable ones. However, remember that blocking systems do not only rely on blocking metrics based on the advantages that proxies give you. So, you may need to adapt this script with other techniques for evading anti-scraping systems, like user-agent rotation and others.
The Web Scraping Club is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Conclusion
In this article, we discussed proxies and their role in web scraping. In particular, the core focus was a comparison between residential and mobile proxies. We evaluated them on specific criteria and provided practical guidance for selecting the best proxy type based on your specific needs.
While mobile proxies offer distinct advantages in certain scenarios, it's a common misconception that they are always a necessity. The best choice truly depends on the specific scraping target and your operational requirements.
So, what’s your experience with mobile and residential proxies? Have you found residential proxies to be sufficient for your needs, or do mobile proxies make a significant difference in your scraping projects? Let’s discuss in the comments!
Just a couple of additions that might be interesting for readers:
IPv4 vs IPv6: The article doesn't mention the difference between IPv4 and IPv6 proxies. From a scraping perspective, it's worth noting that some target websites outright block IPv6 traffic, which can render IPv6 proxies useless in those cases. On the other hand, IPv6 addresses are more abundant, potentially allowing longer rotations and sometimes lower costs. It's a tradeoff worth mentioning.
Cost-optimized proxy strategy: One useful approach we've seen across multiple users is starting each request with the cheapest proxy type available (typically datacenter). If the request fails or gets blocked, the system retries with a residential proxy. If that also fails, it escalates to a mobile proxy. This fallback chain ensures both cost-efficiency and high success rates.
Session reuse with sticky residential IPs: Some of our users implement a smart technique with sticky residential proxies. They check the assigned IP before starting a scraping session. If the IP has been used by them before, they reload the exact same browser session they used before with the IP (persistent context). This way, any cookies or local storage values placed there by the target site's anti-bot system are preserved. Since both the IP and browser context match, trust signals are maximized.










Great article, thanks for the summary!
Just a couple of additions that might be interesting for readers:
IPv4 vs IPv6: The article doesn't mention the difference between IPv4 and IPv6 proxies. From a scraping perspective, it's worth noting that some target websites outright block IPv6 traffic, which can render IPv6 proxies useless in those cases. On the other hand, IPv6 addresses are more abundant, potentially allowing longer rotations and sometimes lower costs. It's a tradeoff worth mentioning.
Cost-optimized proxy strategy: One useful approach we've seen across multiple users is starting each request with the cheapest proxy type available (typically datacenter). If the request fails or gets blocked, the system retries with a residential proxy. If that also fails, it escalates to a mobile proxy. This fallback chain ensures both cost-efficiency and high success rates.
Session reuse with sticky residential IPs: Some of our users implement a smart technique with sticky residential proxies. They check the assigned IP before starting a scraping session. If the IP has been used by them before, they reload the exact same browser session they used before with the IP (persistent context). This way, any cookies or local storage values placed there by the target site's anti-bot system are preserved. Since both the IP and browser context match, trust signals are maximized.
Hope this adds value to the discussion!