
Web scraping from 0 to hero: creating our first Scrapy spider - Part 1
How to scrape a website with Scrapy, starting from scratch

Welcome back to the free web scraping course provided by The Web Scraping Club.
In the past lessons we have explored the preliminary phase of a web scraping project but today we’ll make our hands dirty by creating our first scraper. It will be a basic one, on a simple e-commerce website without any anti-bot in place.
Lesson pre-requirements
In this chapter of the course, you will see a practical example of a web scraping project: since I’m more proficient in Python, we’ll use that as a programming language, so you’ll need a basic understanding of it to understand the lesson fully.
We’ll also use Scrapy as a framework for writing our first scraper, so you should have it already installed on your machine. I won’t cover the installation and setup part since it’s already fully explained on the official documentation page.
How the course works
The course is and will be always free. As always, I’m here to share and not to make you buy something. If you want to say “thank you”, consider subscribing to this substack with a paid plan. It’s not mandatory but appreciated, and you’ll get access to the whole “The LAB” articles archive, with 30+ practical articles on more complex topics and its code repository.
We’ll see free-to-use packages and solutions and if there will be some commercial ones, it’s because they are solutions that I’ve already tested and solve issues I cannot do in other ways.
At first, I imagined this course being a monthly issue but as I was writing down the table of content, I realized it would take years to complete writing it. So probably it will have a bi-weekly frequency, filling the gaps in the publishing plan without taking too much space at the expense of more in-depth articles.
The collection of articles can be found using the tag WSF0TH and there will be a section on the main substack page.
Understanding the data needs
Every web scraping project starts with some requirements and writing them down simplifies the following steps.
Define the target website
It seems obvious if you work in the web scraping industry, but understanding which is the target website is key.
You cannot imagine how many times I’ve received some inquiries for web scraping projects, and when I asked about the target websites, the person in front of me didn’t even know them, just wanted some random data from the web about a certain topic, maybe from hundreds of websites.
Defining a clear target website helps you with planning the work, makes you clearer the plausible costs of the project, and allows you to understand if the task is something that can be done in compliance with the privacy and copyright laws.
In our example, we want to scrape e-commerce pricing data from the Valentino.com website, in its UK version. Since prices change from country to country, the target country must be set and clear before starting to write the first line of code. In fact, it’s not rare that the same website has different versions according to the visited country.

After we assessed that the website is publicly accessible without any login, the first check we can make from a legal perspective is passed.
Another aspect to care about when designing our web scraping process is the refresh rate of the data: do we need a one-off project, a daily refresh, or even an infra-daily refresh?
Depending on the answer, the project and its costs could be very different. In this case, where we wanted only to write our first scraper, let’s consider it as a one-off project.
Defining the output data and format
Now we need to understand what’s the desired output data, for a clearer view of the scope of the project.
This will help us in the phase of data discovery on the website and also the setup of the scraper.
Let’s suppose the output data should contain the following values:
product code
full price
price
currency code
country code
item URL
image URL
product name
gender
product category
product subcategory
Again, from a legal perspective, it seems all legit. There are no copyrighted materials since product prices are factual and we’re not storing any images but only using a URL to point at them.
Now we need to understand where to get this data from.
It seems we can get all these fields from the product list pages like this one instead of entering every product page, saving a great number of requests and reducing the workload for the target website.

Except for the product code, which is not exposed, all the other fields are visible from the product list pages.
In the case of discounts, the prices are exposed in a different format, so probably we’ll have different selectors to consider when it comes to these fields.

Regarding the output data format, Scrapy has embedded some functions that allow the creation of files with the most common data formats, like CSV and JSON. We’ll save our data in CSV files.
Check the anti-bot presence
The last thing before starting coding is to check if there’s any anti-bot software on the website, in order to choose the proper tool to use for scraping.
This can be done quickly by using the Wappalyzer browser extension, which in this case, under the security tab, returns only Riskified and HSTS.
These are not solutions aimed at preventing web scraping, like Akamai, Cloudflare, Datadome, and so on, so we should not worry about them and keep our scraper simple by using Scrapy.
Creating the scraper
Set up the environment
Once Scrapy is installed on our system, the first thing needed is to create a Scrapy project, which will contain every file needed from the scraper.
On Unix, let’s create a directory and then, inside of it, the Scrapy project. You will find the code in The Web Scraping Club free repository on GitHub.
mkdir ourfirstscraper
cd ourfirstscraper
scrapy startproject valentinoAfter running these commands, on the directory ourfirstscraper, we’ll see a series of files and directories needed by our scraper.
Inside the project directory valentino we have the scrapy.cfg file, where basically set the path to the settings.py file and the instruction for deploying to Scrapyd-based schedulers. At the moment, we don’t need to touch anything here.
Opening the directory valentino, we have the following files:
items.py, where we define the data structures of Items, which are the output of the scrapers
middlewares.py, in case we need to write our custom middleware. We’ll see in another lesson what middleware is.
settings.py, where we’ll set all the hundreds of parameters of the scrapers. Just to have an idea about the level of customization we can reach, you can check in the GitHub repository what are the default settings of a spider.
pipelines.py in case we need to implement some methods to work on items after they have been scraped. Typically some methods implemented are about data cleaning or deduplication.

For now, we’re only going to work on the items.py file, where we’ll define the output columns of the scraper, based on the business requirements seen before.
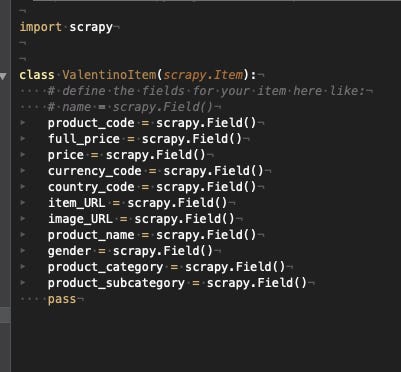
In this case, we’ve set all the fields as scrapy generic fields, but we could eventually define them as integers or other formats.
Now, let’s create the skeleton for the real scraping program. In the terminal, let’s launch this command, after entering the valentino folder
scrapy genspider ecomscraper valentino.comWe’re generating a scraper called ecomscraper which is allowed to crawl only the domain valentino.com.

This command generated the ecomscraper.py file in the spider folder and now we’ll work on it to create the real scraper.
Scraping the website
The previous command created this skeleton of scraper.
import scrapy
class EcomscraperSpider(scrapy.Spider):
name = "ecomscraper"
allowed_domains = ["valentino.com"]
start_urls = ["https://valentino.com"]
def parse(self, response):
passIt says that our spider, called ecomscraper, is allowed to crawl only valentino.com, starting from the URL https://www.valentino.com.
After making a request to this first page, the response will be sent to the function parse, where we’ll write the logic of the scraper.
Let’s fix the starting URL first since we need to start from the UK version of the website.
start_urls = ["https://www.valentino.com/en-gb/"]Now we need to extract all the URLs of the different product categories available on the website, to scrape all the product prices.
Since we’re using Scrapy and not any browser that renders the page, we need to have a look at the raw HTML of the page to understand where the product category’s links to follow.
Using the right-click of the mouse on the main page and then “view page source”, we’ll see that.
One trick I use when I need to understand what’s the HTML structure of a menu is this: I select manually one URL I need to find programmatically, like https://www.valentino.com/en-gb/women/bags/shoulder-bags, and search in the HTML its ending part, like “women/bags/shoulder-bags”. I’m not looking for the whole URL since maybe they are relative URLs in the code.
In this case, I’m finding this HTML structure
<a href="https://www.valentino.com/en-gb/women/bags/shoulder-bags" class="column-element"><span>Shoulder Bags</span></a>which is repeated for every voice in the main menu of the website.
Let’s get every voice of the menu programmatically and print it on screen.
categories = response.xpath('//a[@class="column-element"]/@href').extract()
for category in categories:
print(category)With this simple portion of code we’re basically reading the HTML response of the main page of the website and, using an XPATH selector, we’re listing all the “href” attributes of nodes named “A” that have the class attribute equal to “column-element”.
Don’t worry, we’ll have a deep dive on XPATH selectors, but if you want to learn more, here’s a great tutorial on XPATH syntax.

It seems we’re getting what we need and, for today it’s enough.
We created our first scraper from scratch, we’ve seen how to do our due diligence to the requests we’re receiving, where to find out the content we need, and wrote down the first XPATH selector to print out the full menu of product categories on the website.
In the next episode, we’ll see how to use this list as a feed of a new function, which returns scraped items and scrolls the product categories until it reaches the last item.