
I wrote my first scraper with ChatGPT
Using Scrapeghost for your web scraping projects

Let’s continue our articles about web scraping and AI and today I’m sharing with you how I created my first scraper using ChatGPT via Scrapeghost.

What is Scrapeghost?
Scrapeghost is a Python package and command line interface that basically makes Python requests and then sends the response as a prompt to ChatGPT, together with a data dictionary. ChatGPT will try to map each field to the most plausible string in the HTML and return the results.
Due to the technical constraints in writing the prompts and the limits imposed by Scrapeghost in the output to parse, it can be challenging to write a new scraper, but my curiosity for this approach wanted me to try it anyway.
Setting up Scrapeghost
Setting up Scrapeghost is a piece of cake, all you need is to install the Python package via pip and declare your OpenAI key in the terminal before launching the scraper. It’s all written in the documentation at this page.
Scrapeghost features
As we said before, Scrapeghost makes some Python requests to a website, retrieves the HTML code from it and passes it to ChatGPT as a prompt, together with the desired output’s data structure. As an additional feature, you can pass directly the HTML already retrieved, so you can use Scrapeghost in combination with Scrapy or Playwright if a simple Python request is not enough for getting it.
Since the prompt cannot be longer than 4000 bytes to avoid the usage of too many API tokens, you can tell your scraper to don’t parse all the HTML code but some parts of it, specifying some CSS or XPATH selectors in the so called preprocessor.
If the page contains multiple items to be returned, like a product list page, the HTML code can be splitted, again to bypass the token limit.
Some custom instructions can also be added to the prompt, in case you need to refine the output of the scraper.
All these functions will be used in the next example, where we’ll try to build a scraper for Valentino.com websites.
Building the scraper
As said before, we’re building a scraper for Valentino’s website. In particular, I want to scrape the details of all the bags contained in this page.

To do so, first I’ll need to extract all the product’s URLs contained in the page and then pass them to a second scraper that retrieves the details.

The first task is quite trivial. We define an output schema containing only the url as a field, and an XPATH of a note that contains it. We split the length of the code to 2000 tokens and write the results in a CSV file.
schema={
"url": "url"
}
scrape_urls = SchemaScraper(
schema,
auto_split_length=2000,
extra_preprocessors=[XPath('//div[@class="productCard"]')],
)
resp = scrape_urls("https://www.valentino.com/en-gb/men/bags")
resp.data
print(resp.data)
for item in resp.data:
with open("urls.txt", "a") as file_b:
csv_file_b = csv.writer(file_b, delimiter="|")
try:
csv_file_b.writerow([item['url'] ])
except:
pass
file_b.close()
The first results are correct, pretty easy!
https://www.valentino.com/en-gb/product-black-iconographe-nylon-belt-bag-YB0C31CSH_0NO
https://www.valentino.com/en-gb/product-le-troisi%C3%A8me-rubber-shopping-bag-WB0M00QGX_GF9
https://www.valentino.com/en-gb/product-le-troisi%C3%A8me-rubber-shopping-bag-WB0M00QGX_K4S
https://www.valentino.com/en-gb/product-le-troisi%C3%A8me-rubber-shopping-bag-WB0M00QGX_KG8
https://www.valentino.com/en-gb/product-le-troisieme-rubber-shopping-bag-YB0C10XLU_0NO
https://www.valentino.com/en-gb/product-le-troisieme-toile-iconographe-large-shopper-YB0C07JXD_U02
https://www.valentino.com/en-gb/product-le-troisieme-toile-iconographe-shopping-bag-YB0C08JXD_U02
https://www.valentino.com/en-gb/product-le-troisieme-toile-iconographe-shopping-bag-YB0C08MDG_6ZN
https://www.valentino.com/en-gb/product-le-troisieme-toile-iconographe-shopping-bag-YB0C08MDG_J4AThe second scraper requires some tricks to work. If we try to pass the whole page to ChatGPT we incur in the token limit error, so we need to split the requests in more parts. At the end of a quite long trial and error phase, analyzing the HTML I’ve decided to use three different scrapers for the three different sections of the product page containing the information needed.
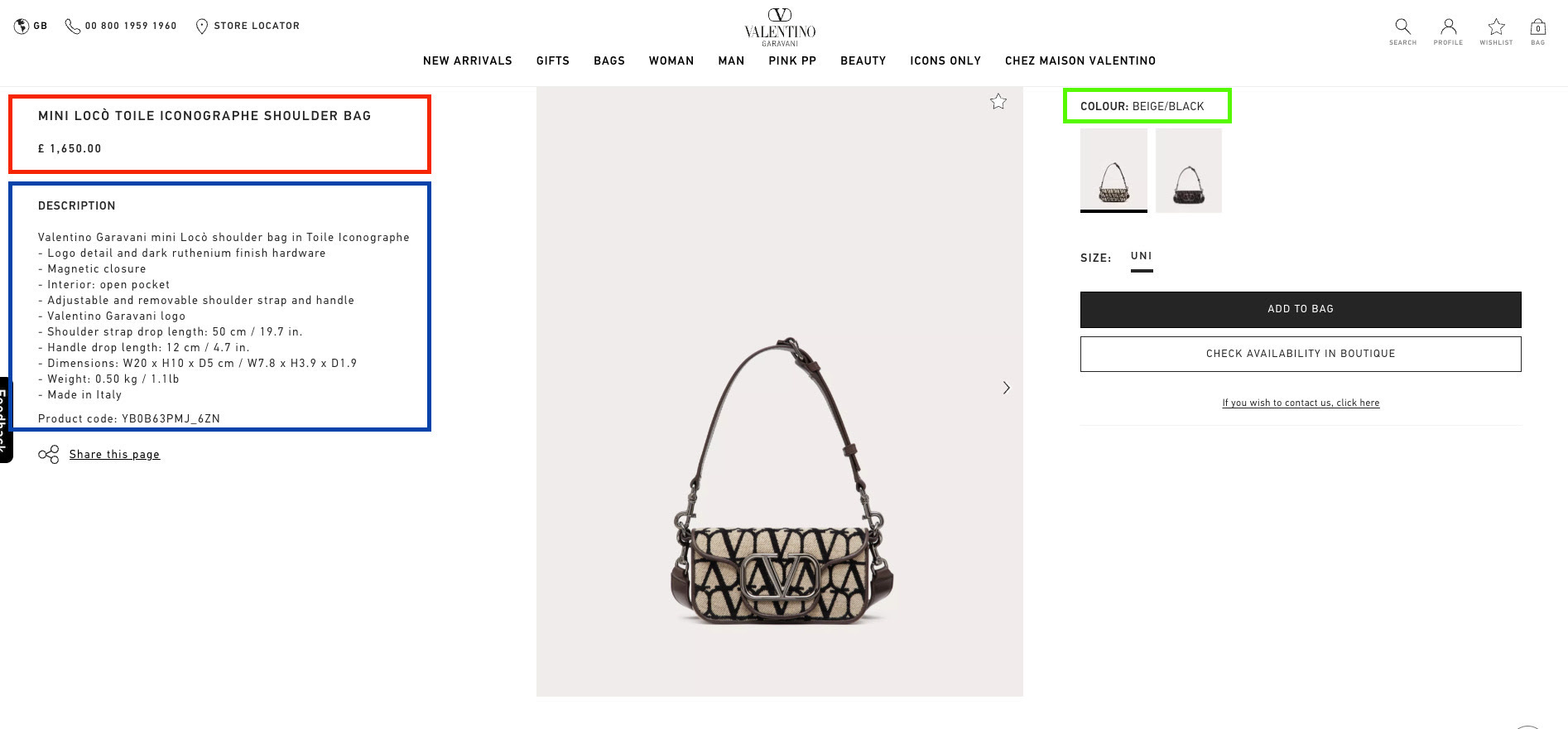
Per each section I’ve declared an XPATH selector that identifies it and an output dictionary for the scraper and here we have the resulting code.
schema_left={
"product_name": "text",
"price" : "text",
"price_without_discounts" : "text",
}
scrape_prod_details_left = SchemaScraper(
schema_left,
extra_preprocessors=[XPath('//section[@class="productInfo"]')],
)
schema_desc={
"description": "text",
"product_code" : "text",
}
scrape_prod_details_desc = SchemaScraper(
schema_desc,
extra_preprocessors=[XPath('//section[contains(@class, "productDescription")]')],
)
schema_right={
"color_name" : "text"
}
scrape_prod_details_right = SchemaScraper(
schema_right,
extra_preprocessors=[XPath('//section[@class="pdpColorSelection"]')],
)
url_file = open('urls.txt')
LOCATIONS = url_file.readlines()
for url in LOCATIONS:
try:
resp = scrape_prod_details_left(url)
data_left=resp.data
resp = scrape_prod_details_desc(url)
data_desc=resp.data
resp = scrape_prod_details_right(url)
data_right=resp.data
try:
product_name= data_left['product_name']
except:
product_name= data_left[0]['product_name']
try:
description = data_desc['description'].replace('\n', ' ')
except:
description = data_desc[0]['description'].replace('\n', ' ')
try:
price = data_left['price']
except:
price = data_left[0]['price']
try:
price_full = data_left['price_without_discounts']
except:
price_full = data_left[0]['price_without_discounts']
try:
productcode = data_desc['product_code']
except:
productcode = data_desc[0]['product_code']
with open("products.txt", "a") as file_b:
csv_file_b = csv.writer(file_b, delimiter="|")
csv_file_b.writerow([product_name,description,price,price_full,productcode,data_right ])
file_b.close()
except:
passYou may have noticed the Try/Except clause for the output fields. I needed to add it because, in several occasions, the block containing the product description returned multiple times the same result inside the output JSON, so I needed to handle these cases.
Another issue with this version of the scraper is that the data_right result JSON is not consistent from one result to another one. We have cases where the the result field is called COLOUR, like on the website, others where is called color_name like I declared in the scraper or others where the color stands as a field name.
{'FONDANTBLACK': 'COLOUR'}
{'COLOUR': 'BLACK'}
{'color_name': 'ROSE CANNELLE'}Probably this can be fixed with an additional prompt in the scraper.
In fact, if we modify the scraper in this way, results are much better:
scrape_prod_details_right = SchemaScraper(
schema_right,
extra_preprocessors=[XPath('//section[@class="pdpColorSelection"]')],
extra_instructions=["Put the color name in the color_name field"],
){'color_name': 'BLACK'}
{'color_name': 'ROSE CANNELLE'}
{'color_name': 'POWDER ROSE'}
{'color_name': 'FONDANT'}Final remarks
The final results of the scrapers look like the following rows
BLACK ICONOGRAPHE NYLON BELT BAG|Valentino Garavani Black Iconographe nylon belt bag-Palladium-finish hardware-Zip closure-Adjustable ribbon belt-Inside: open pocket-Valentino Garavani logo-Dimensions: W29 x H12 cm / 11.4 x 4.7 in.-Weight: 0.2 kg / 0.4 lb-Made in Italy|£ 690.00||YB0C31CSH_0NO|BLACK
LE TROISIÈME RUBBER SHOPPING BAG|Valentino Garavani Le Troisième rubber shopping bag with studded pattern. The bag features shaped handles. <br>- Dimensions: W40 x H25 x D17 cm / W1.6 x H9.8 x D6.7 in. <br>- Made in Italy|£ 1,100.00||Product code: WB0M00QGX_GF9|ROSE CANNELLE
LE TROISIÈME RUBBER SHOPPING BAG|Valentino Garavani Le Troisième rubber shopping bag with studded pattern. The bag features shaped handles. <br>- Dimensions: W40 x H25 x D17 cm / W1.6 x H9.8 x D6.7 in. <br>- Made in Italy|£ 1,100.00||Product code: WB0M00QGX_K4S|POWDER ROSE
LE TROISIÈME RUBBER SHOPPING BAG|Valentino Garavani Le Troisième rubber shopping bag with studded pattern. The bag features shaped handles. <br>- Dimensions: W40 x H25 x D17 cm / W1.6 x H9.8 x D6.7 in. <br>- Made in Italy|£ 1,100.00||Product code: WB0M00QGX_KG8|FONDANT
LE TROISIEME RUBBER SHOPPING BAG|Valentino Garavani Le Troisième rubber shopping bag with studded pattern. The bag features shaped handles. <br>- Dimensions: W40xH25xD17 cm / W1.6xH9.8xD6.7 in. <br>- Made in Italy|£ 1,090.00||YB0C10XLU_0NO|BLACKWe get the right data in the right field, except the field product without discount. Probabily it’s a business concept and, without any discount on the website, ChatGPT doesn’t know what to do with this field.
If we consider the mere time for writing the scraper, in this case Scrapeghost didn’t help saving time. What we saved in time to write the XPATH for every field, was lost for finding the right HTML split for the different executions.
In a future prospective, this solution could save us time since we don’t have many XPATH expressions to fix in case the website changes, but only one per execution.
The real concerns are the following:
this solution is slow and expensive, and this depends from ChatGPT. The execution times at the moment are too slow, compared to a simple Scrapy spider. And, on top of the server where the scraper runs, we also need to pay OpenAI for the usage of the API. While each token costs few cents, it’s something unfeasable at the moment for a large web scraping project.
in case a field is not correctly mapped, I’m not sure I could always fix it by adding other instructions in the prompt. It will be always a trial and error process, since ChatGPT is a black box and could be frustrating.
Despite being not suitable for a large web scraping project in production, this kind of solution can be good for a proof of concept or some tests, but I need to admit it’s been funny to create this scraper.