
Building a generic scraper for multiple websites
Handling multiple extractions with only one scraper: myth or reality?

One of the most common questions I hear when people approach a new web scraping project involving multiple websites is: “ Do I need one scraper per website, or can I write a generic one to handle them?”
I asked myself this question several times in my career, and despite the web evolving by introducing more standards, especially for SEO purposes, I’ve always opted for building a dedicated scraper for each file.
Given the rise of new AI tools, in today’s article, I’m looking for new solutions to this problem, which is as old as web scraping.
Finding the most efficient way to scrape a website is one of the services we offer in our consulting tasks, in addition to projects aimed at boosting the cost efficiency and scalability of your scraping operations. Want to know more? Let’s get in touch.
The traditional approach
Let’s say we have ten websites to scrape. They are all e-commerce websites, and we want to create a structured output with a standard data structure. We want to get the product code, full and final prices with currency code, product category, the item URL, the main image URL, and the product name.
In a perfect world, where standards are applied to every website without exceptions and in the most exhaustive way, we would already have the solution: use the schema.org JSON inside web pages.
What is Schema.org?
Launched in June 2011 as a collaborative initiative between major search engines like Google, Bing, Yahoo!, and Yandex, Schema.org provides a collection of shared vocabularies that webmasters can use to make their websites more readable by machines. By incorporating Schema.org markup, websites can help search engines better understand their content, leading to more informative and engaging search results for users.
We have the proper markup for each use case: events, location, and products are just a few of the available ones. Since our example is based on e-commerce websites, let’s focus on the product schema.
The 'Product' Schema in E-commerce
The 'Product' schema is particularly significant for e-commerce websites. It lets retailers provide detailed product information directly within their site's HTML. This structured data includes essential product attributes such as name, image, description, brand, price, availability, and customer reviews.
Key Elements of the 'Product' Schema:
Name: The official product name.
Image: High-quality images of the product.
Description: A detailed description highlighting features and benefits.
Brand: The manufacturer or brand of the product.
SKU: Stock Keeping Unit identifier.
Offers: Pricing information, including discounts or special offers.
AggregateRating: Overall rating based on multiple customer reviews.
Review: Individual customer reviews and ratings.
Benefits of Using the 'Product' Schema:
Enhanced Search Listings: Products marked up with the 'Product' schema can appear in search results with rich snippets, displaying additional information like ratings, prices, and availability. This makes listings more attractive to potential customers.
Improved SEO Performance: Structured data helps search engines index and rank pages more effectively, potentially improving organic search rankings.
Increased Click-Through Rates: Rich snippets provide users with more context, increasing the likelihood they'll click on your link over a competitor's.
Better User Experience: Providing detailed product information directly in search results enhances user satisfaction and trust.
Adoption in the E-commerce Industry
Adopting the 'Product' schema has grown steadily as retailers recognize its value. Major e-commerce platforms like Shopify, Magento, and WooCommerce offer built-in support or plugins to implement Schema.org markup easily. Additionally, with the rise of voice search and virtual assistants, structured data has become even more critical for ensuring products are discoverable across different search modalities.
So, life is easy for web scrapers. Or not?
Schema.org standards are suggested and are good SEO practices but not mandatory, so poorly designed websites may miss them.
The fields are not constrained, so even if there’s a product schema, it may lack key data. Take a look at these two examples:

In this first case, extracted from a product on the Dolce e Gabbana website, the schema is highly detailed, but we’re missing a critical detail: the product price.
In another example from the Yoox website, we have the final price but not the original price without discounts.
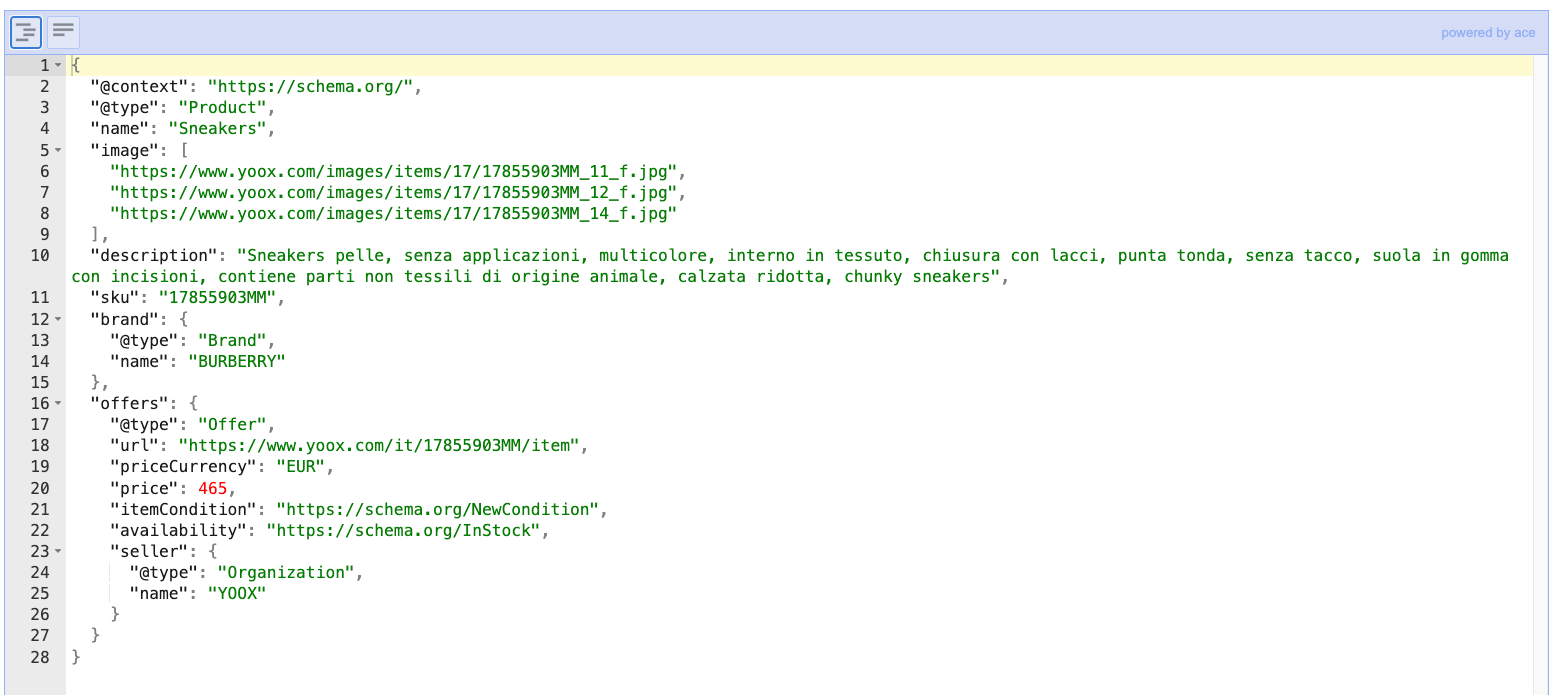
These are just two examples, and we already can see the main issue: the web has a long tail of websites we can encounter, with different sets of fields exposed on the Schema.org JSON. We may need to integrate our scrapers with custom XPATH selectors for the missing fields per website, leading to a tremendous and unreadable monolith of code in the worst scenario.
The post-LLM world approach
One of LLMs' many applications is extracting meaningful information from code or documents. We’re seeing a boom of LLM-powered scraping tools, such as Skyvern, ScrapeGraph AI, and Firecrawl, just to mention the most famous open-source projects.
Continuing with our example, delegating the scraping task to a third-party tool should meet a list of requirements if we decide to follow this route.
First, the tool should be able to extract information from the long tail of the web and return a fixed data schema. This means that we should be able to fix the output in case the LLM returns a wrong result, but also that the tool should be able to bypass all the anti-bot softwares we could meet.
This is the reason why companies specialized in this task, like Zyte, Nimble, Bright Data, and ultimately Oxylabs, are releasing AI-powered tools: parsing is just one of the pain points of web scraping, but anti-bot bypassing is the most painful and expensive one, in terms of money and time required.
Is this a viable solution for a project in production?
We discussed creating a generic web scraper to extract data from ten e-commerce websites. But is this doable on a real-world project?
I cherry-picked ten different websites with different anti-bot protections and structures and used them inside to test the Zyte API, the AI-powered solution by Zyte.
Zyte API allows you to create scrapers without worrying about anti-bot solutions and data parsing since it provides pre-defined output data structures for products, articles, job postings, etc. You can even create your custom schema and use it for your scrapers.
I decided to stress-test the API by creating a scraper divided into two functions:
The first one uses the product navigation output schema. Given an e-commerce product list page, it returns the list of product URLs and the next page of the catalog. I decided to stress test this part by adding some websites with infinite scroll or particular pagination to the input.
Since the product list output doesn’t contain all the fields we need (we’re missing the brand field, which is crucial when scraping data from multi-brand websites), we’re using the list of URLs extracted before to get the product information from the product API call. To increase the efficiency of this extraction, we could create a custom output schema that adds the brand's name to the product list to save a significant amount of API calls. In this basic example, we’re using the product detail API automap. Again, to test the solution, I’ve chosen websites with different layouts and ways to display promotions.
The websites in the pool are:
Hermes.com, one of the toughest websites to scrape, protected with Datadome
Footlocker.com, protected with Datadome
Farfetch.com, protected by Akamai
Yoox.com, protected by Akamai and with a strange layout for discounts
Zalando.it, protected by Akamai
Saks Fifth Avenue, protected by Akamai, Cloudflare, and Datadome, also has an infinite scroll instead of a traditional pagination
Bloomingdales, protected by Akamai
Canada Goose, protected by Kasada and with infinite scroll instead of the traditional pagination
On running, protected by Cloudflare, and using a “view more” button to paginate
Rene Caovilla, because it’s a semi-unknown website using a “view more” button to paginate
As you can see, I’ve been quite picky, and your basket of websites probably won’t be so variegated, with a mix of famous multi-brand websites and lesser-known mono-brand ones.
Test results
TL;DR version: I didn’t expect such good results, but the Zyte API covered 90% of the surface. With some tweaks, I could make it work for every output field on almost every website.
The major issues encountered were as I supposed them to be:
The Hermes website requires additional work to be bypassed. As far as I know, as of today, there’s no commercial unblocker who’s able to bypass it.
Websites with infinite scrolls, like Saks Fifth Avenue, return only the first page of the category since there’s no link to the next page in the code. Canada Goose, instead, despite having infinite scroll, has a link to the next page in the code so that the API can move to the end of it correctly.
In the On Running website, the link to the next page of a category simply does not exist, so it’s normal for the API to not retrieve it.
As you can see, I carefully selected websites with the worst scenarios possible.
On the parsing side, everything went smoothly for all the websites. The brand field for the mono-brand websites had some issues, but this can be easily fixed in the scraper. Here and there, the brand and category fields are not populated correctly on the Zalando and Yoox websites. Still, this experiment's final result is much better than I expected.
If you want to try it yourself, you need a Zyte API account and the code you can find in the GitHub repository of The Web Scraping Club, open to everyone. The code is in the folder “generic-scraper”
Like this article? Share it with your friends who might have missed it or leave feedback for me about it. It’s important to understand how to improve this newsletter.
You can also invite your friends to subscribe to the newsletter. The more you bring, the bigger prize you get.