
Building a custom GPT using Firecrawl
Create The Web Scraping Club GPT by scraping my own newsletter

Some months ago OpenAI released the feature to create your own tailored GPT model and this opportunity always intrigued me.
The idea of having an omniscient GPT assistant capable of giving me solutions and suggestions on my scraping project is exciting, so I wanted to try to add my knowledge on web scraping on top of a ChatGPT base model.

Why a custom GPT?
Well, the standard ChatGPT model, even using the latest 01-preview, doesn’t give deep answers, if returning any.

Probably this is also due to the constraints put in place by OpenAI in order to make the model don’t suggest any technique to infringe copyrights or terms of services of the websites. If so, I would find that so damn ironic, given the techniques and the volume of the scraping in place in the company.

Side note: it seems there’s a new player in the game, who doesn’t even care about your robots.txt file.

How to create a custom GPT using the ChatGPT web interface?
There are plenty of articles and techniques on the web about this topic, but since I’m not an AI guru and need a slightly better version of ChatGPT with the info extracted from this newsletter, I’ll use the web interface of ChatGPT to create a so-called custom GPT.

If you’re a paying user of ChatGPT you have a menu on the left column of the website where you can explore the GPT marketplace, containing custom GPTs tailored with additional sources of information.
On the top right of the screen, you have the “Create” button, and by clicking it you can start configuring your own.
Once the process starts, I suggest using the “Configure” tab to have more control over the configuration details.

After compiling the first fields with the logo, name, description, the highlighted questions at the start, and the general instructions for the GPT, you can finally upload your knowledge to add to the model.
And here comes the fun part.
Importing knowledge in the GPT
Reading around the forums there’s some debate on what’s the best format for passing your own knowledge to your custom GPT: some say PDF documents are the best, some others Markdown files, so I’ll try both of them and see if there is a real difference, at least in this case.
To scrape my own newsletter about web scraping, which seems to be a movie from Christofer Nolan, I’m using the free plan of Firecrawl, an API that scrapes a URL (or many of them) and returns a markdown file.
Unluckily, I have some issues in using their Python package, I’ve tried everything but got some errors like circular dependencies, so I ended up using cURL, even if it slows me down a bit.
First Test
I decided to use as a test the latest free article, the Wrap-Up of the Oxycon 2024, which is something that the standard GPT is not aware of.
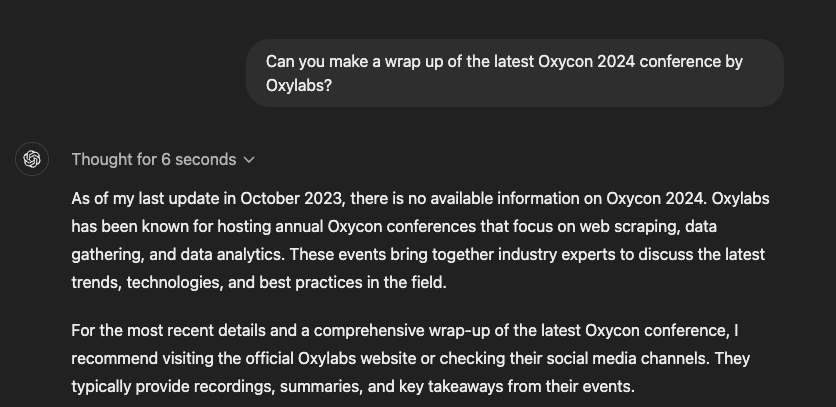
Scraping my content with Firecrawl is a piece of cake, one cURL call is enough to have a markdown.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer MYAPIKEY' \
-d '{"url": "https://substack.thewebscraping.club/p/the-oxycon-2024-wrap-up","formats" : ["markdown"]}' -o Oxycon2024.mdNow I’ve got my file I can upload it to the GPT. Unluckily it’s not so clean, I still have the Substack headers, the name of the newsletters, and other things that might create some confusion, but let’s see if it’s enough for answering to the same question.

Well, it seems so! This is exactly the plot of my latest article!
In an ideal world, I could create a markdown file for every free article I wrote and then upload it to the custom GPT but unluckily this approach has one big limitation: I cannot upload more than 20 files.
But what if I append all the articles in one markdown file? Will GPT be able to read the content even with all the noise around?
It seems anyway that markdown files are a good way to pass knowledge to GPT
Second test
I’ve converted in markdown the latest 20 free articles of The Web Scraping Club, following the same process as before, and then appended one to another.
With some back and forth in the formatting process, the answers the GPT gave me were quite good in most of the topics.
It could answer correctly by reading the articles to the court case of Bright Data vs X, by summarizing the latest legal ZyteGeist

In other cases, the marketing material flooding the internet took over, making GPT ignore my unblocker and anti-detect browser benchmarks and return promotional material read over the web.
It was a nice experiment to make and I’ll try my best to keep the content updated and refine the answers. If you wish to play with it, it’s available to everyone at this link:
Like this article? Share it with your friends who might have missed it or just leave feedback for me about it. It’s important to understand how to improve this newsletter.
You can also invite your friends to subscribe to the newsletter. The more you bring, the bigger prize you get.