
The Lab #55: Checking your browser fingerprint
Understanding your scrapers' browser fingerprint reliability with online tests.

On these pages, I often mention two approaches for bypassing anti-bots: reverse engineering vs creating human-like bots.
While the first is the most effective against one single solution, it’s fragile when the solution changes over time and needs to be reverse-engineered again.
Creating scrapers that look like humans, instead, is a more reliable way to proceed, since it doesn’t require custom-made work based on the solution, but the scrapers need to look as authentic as possible.
Clearly, this means that your solution includes a headful browser, with a human-perfect fingerprint.
But what is a browser fingerprint?
Browser fingerprinting is a sophisticated technique used to identify users based on their browser and device characteristics uniquely. This method collects various data points from a user's web browser, such as browser type, version, operating system, screen resolution, installed fonts and plugins, and more. By analyzing these attributes, a unique "fingerprint" is created that can be used to track and identify users across different browsing sessions and devices. In the early days of the internet, this task was accomplished (and still it is today, but with more limitations due to the increased regulation on them), by cookies.
How effective is browser fingerprinting compared to traditional cookies
Browser fingerprinting is generally more effective than traditional cookies for user identification and tracking. While cookies are easy to block or delete, browser fingerprinting is much more difficult to detect and prevent. Some key advantages of browser fingerprinting over cookies:
Persistence: Browser fingerprints are derived from the characteristics of the user's device and browser, making them more persistent than cookies which can be easily deleted.
Uniqueness: The combination of attributes collected in a browser fingerprint is highly unique, with studies finding that over 80% of browsers are identifiable.
Evasion resistance: Blocking or spoofing browser fingerprinting is challenging since the data collected is essential for websites to function properly. Even using privacy-focused browsers or extensions can paradoxically make a device more unique.
Widespread adoption: Browser fingerprinting is already used by a quarter of the top 10,000 websites, and its usage is expected to grow as third-party cookies are phased out.
However, fingerprinting does have some limitations compared to cookies:
Accuracy: While highly unique, browser fingerprints are not as accurate as cookies for identifying individual users, especially across different devices.
Regulation: There are currently no specific regulations governing the use of browser fingerprinting, but this may change in the future as privacy concerns grow.
Usability trade-offs: Fully preventing fingerprinting can negatively impact website functionality and user experience.
How is browser fingerprinting used for web scraping prevention?
The latest version of Chrome has more than 8k Browsers API, as studied in the Web Scraping Enthusiast Discord server.

With all these data points available, cyber-security companies can use them to profile requests and discriminate bots from humans, looking for red flags.
Detecting browser inconsistencies
One key method for identifying bots is looking for browser fingerprint inconsistencies. Legitimate users will have a consistent fingerprint across sessions, with only minor changes as they update their browser or device. Bots, on the other hand, often have inconsistent or rapidly changing fingerprints as they rotate IP addresses, user agents, and other attributes to avoid detection. Even some popular tools used for scraping create inconsistencies, since they change partially the attributes of the browsers but don’t have access to others.
Analyzing browser API usage
Bots often use browser APIs differently than human users. For example, bots may make a large number of requests in a short time, or they may not properly handle certain API responses. By analyzing the usage patterns of APIs like XMLHttpRequest, Canvas, WebGL, and more, fingerprinting can identify bot-like behavior.
Detecting headless browsers
Many bots use headless browsers, which are web browsers without a graphical user interface. These are often used to automate web interactions and extract data. However, headless browsers can be detected by analyzing attributes like the user agent string, screen size, and font list, which are often different from regular browsers.
What are the main browser APIs used for bot detection?
Several browser APIs are commonly used in browser fingerprinting for bot detection:
User Agent: The user agent string provides information about the browser, operating system, and device.
Screen Size and Color Depth: The screen size and color depth can be used to identify devices and detect headless browsers.
Installed Fonts: The list of installed fonts is a unique attribute that can be used to fingerprint devices.
WebGL and Canvas: These APIs can be used to extract information about the device's graphics hardware and detect bots.
Audio: The Web Audio API can be used to collect information about the user's audio hardware.
Battery: The Battery Status API can provide information about the device's battery, which can be used as a unique identifier.
Timezone: The timezone can be used to infer the user's location and detect bots.
Language: The language settings can provide information about the user's location and preferences.
Audio, video, and camera device numbers: if a scraper is running from a server, it won’t have any audio and video device, which is quite strange for consumer-grade hardware.
WebGL renderer: servers don’t need GPUs, so they will probably use the Swiftshader renderer.
How to check meaningful browser attributes for your scraper?
Antoine Vastel, head of research at Datadome, created a useful web page where you can check the browser’s attributes and use it as a benchmark for your scraper.
Today we’ll use this page as a benchmark for the different solutions we’ll see together.
As always, if you want to have a look at the code, you can access the GitHub repository, available for paying readers. You can find this example inside the folder 55.FINGERPRINT-TEST
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to get it.
A consistent fingerprint: mine
Let’s have a look at what my fingerprint looks like when I’m browsing this page.

The headers are not a surprise, and they’re the easiest part to mimic in our scrapers, even in Scrapy.
The device information section is the most interesting one
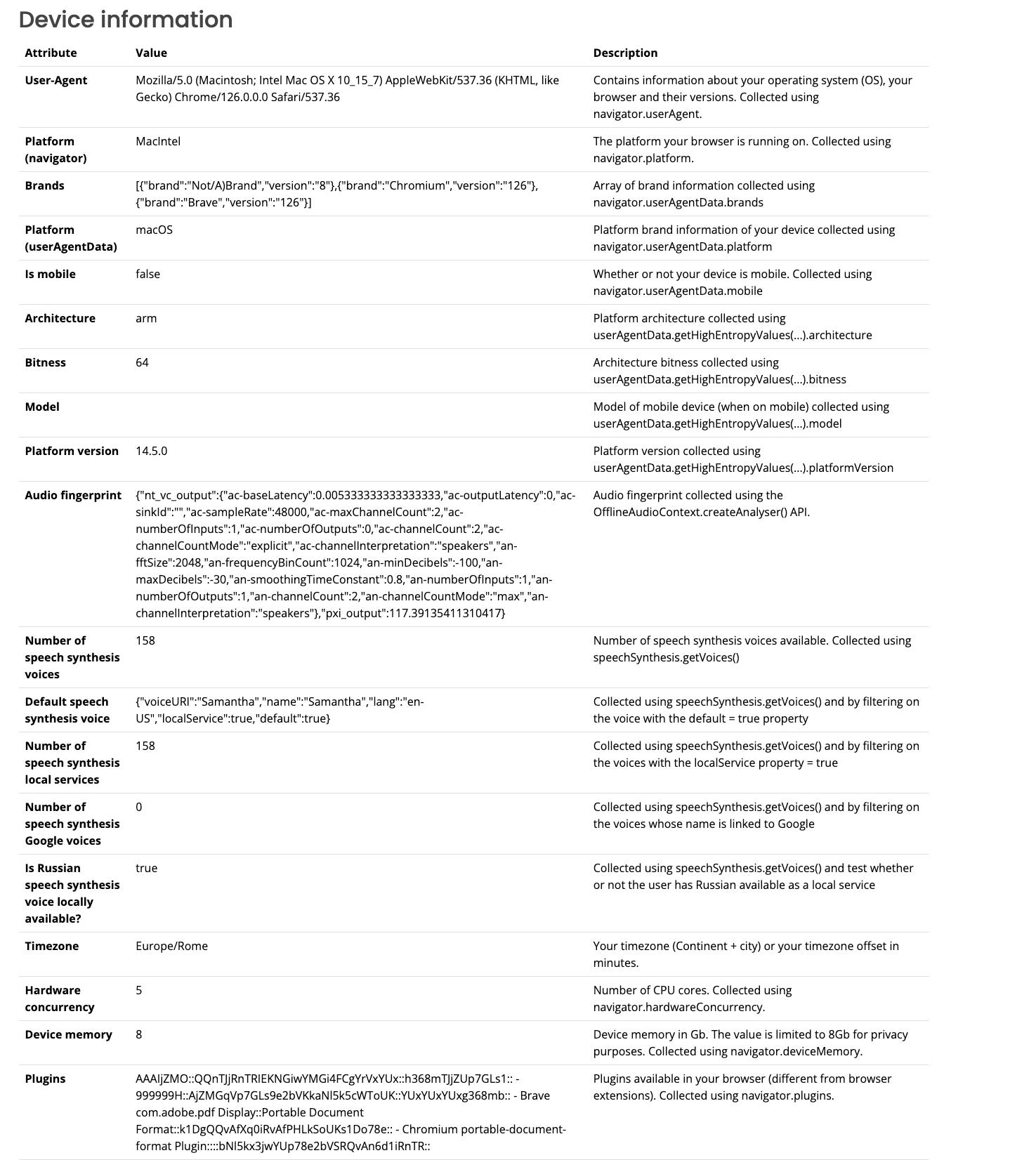
You can see the machine type I’m using (A desktop Mac), its audio setup, the memory, and CPU architecture.
After other values that I won’t report here, here are the hidden gems for detecting the browser automation tools

Plain vanilla Playwright from my desktop
Let’s see how some of these values change when, instead of browsing, I’m opening this page with Playwright and Chromium, with no other additional option (run_playwright_vanilla command in the tests.py file).

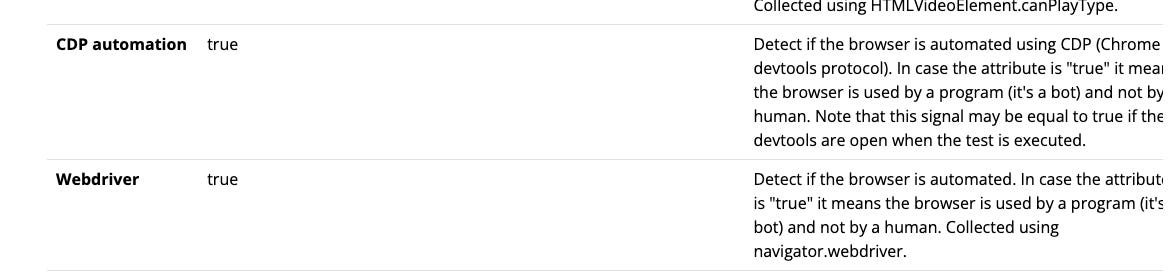
The window opened by Playwright is smaller and the automation framework is detected by the webdriver flag. It’s also interesting that, even if I’m not using CDP to connect to Playwright, the test detects it.
Playwright with Chrome and some camouflage
By slightly changing the previous scraper, adding some options, and disabling the webdriver value, the situation improved a bit. The function is called run_chrome in the same tests.py file.
CHROMIUM_ARGS= [
'--no-first-run',
'--disable-blink-features=AutomationControlled',
'--start-maximized'
]
browser = playwright.chromium.launch(channel="chrome", headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
context = browser.new_context(
no_viewport=True
)
We still have the CDP flag set to true, while the rest of the fingerprint is plausible since I’m running this test from my Mac.
Let’s see the differences when running it from an AWS machine.
Playwright with Chrome on AWS
Running the same script (run_chrome) from an AWS machine, we can see in action how the browser describes the underlying hardware.
While the flags about browser automation keep the same values as before, what’s changing is the description of the machine that the browser is creating.


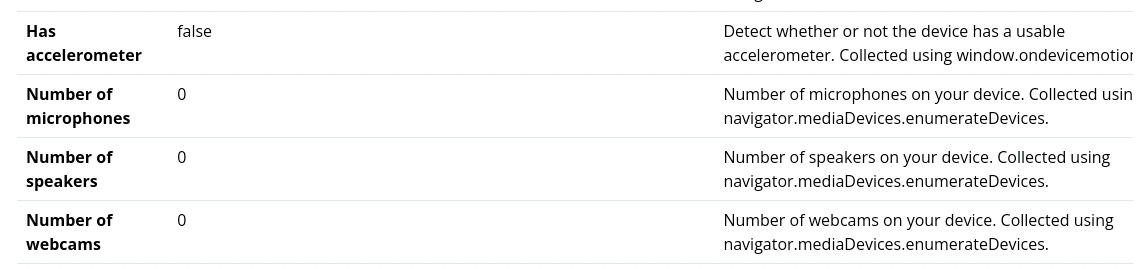

The number of audio, microphones, and webcams, together with the GPU renderer, are big red flags for anti-bots.
But what we can do to mitigate this situation?
Injecting a fingerprint with Browserforge
