
Browser API: an introduction
How anti-bot retrieve information to create fingerprints

When creating a new web scraper, especially if we know the target website has some anti-bot protection, it can be useful to test the tech stack used using online pages like Sannysoft
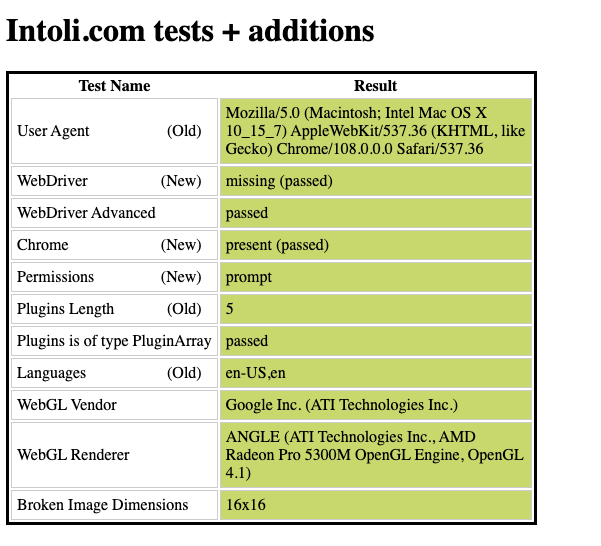
They basically test our browser’s Web API and attributes like the Window.Navigator and check if the values are plausible or not for a human being browsing the web.
But let’s take a step back.
Web API: creating order in the complexity of the modern web
If you’re on these pages, I’m pretty sure you’ve already heard about APIs (application program interfaces). They’re basically a way to communicate with other systems without knowing many of their details. You need to make a request to an endpoint, with proper parameters, and you get the results. What happens in the background stays out of your sight. You connect to the Twitter API to get the latest post from your account with a single request, without knowing how data is stored in Twitter’s database and writing the query to pull data out of it.
This kind of APIs is classified as server-side API, as we connect to a server to get data from there.
As you can imagine, there are also client-side APIs that work similarly but make their way back. The website we’re visiting uses API built inside our browsers to get data and perform actions using these responses.
But while the reason behind server-side APIs is apparent to everyone, why there’s a need for client-side APIs?
Simply put, the web has changed, of course, from the 80’s to today.
There are way more layers of technology to consider when creating a website. Interacting with the graphic card, tuning the definition according to the hardware configuration, how to store data on the client, managing the audio interface, different browsers and device types, and much more.
Today, every browser exposes hundreds of pieces of information about itself, the hardware configuration where it runs, the extensions installed, navigation data, and so on. If you want an extended list of all the client APIs available in your browser, here’s the complete list with documentation on the Mozilla developer portal.
Browser API and web scraping
While all this information can be used to enhance our web experience, adapting the features to our hardware configuration, it’s also the basis for what’s called fingerprinting, a theme we often cover on these pages.
A fingerprint, in fact, it’s the sum of all relevant data retrieved from the browser (and the IP), mixed together and encoded using proprietary algorithms.
So when we need to use automated browsers to scrape a website, we need to consider what we’re sending out a huge amount of information about the running environment which these software are getting more and more able to exploit in order to block bots.
This means that nowadays, the secret sauce of web scraping is to make the scraper look as much as possible like a human browsing a website, both from a behavioral point of view and as a tech stack.
Leaving aside the behavioral aspects of the scraper, which is a programming issue, how can our scraper go unnoticed by anti-bots?
Simplifying a bit, the browser APIs can be divided into three main groups, depending on the source of the information they expose.
Hardware related information
Browser related information
Location data
The Holy Grail for web scraping is, in fact, automating scraping operations using a real browser running a desktop computer inside a residential building. It would be almost impossible to detect but, of course, this solution has some bottlenecks when it comes to a production environment.
So how should a web scraper that uses a browser be built to be undetected?
Location data
About the location data passed by the browser, it all depends on the IP we’re using for scraping. In order to select which country should be displayed and the type of IP address the requests are coming from, you can easily use one of the many proxy providers available.
Browser related information
Here the devil is in the details. While we have many libraries available for web scraping, finding the correct configuration and tricks makes the difference.
Here’s an example to understand better what I mean.
The navigator.webdriver flag
The navigator.webdriver flag is one browser attribute that raises red flags in case of misconfiguration. In fact, it indicates whether the user agent is controlled by automation software and it’s one of the first things checked by the Sannybot test.
If we take the Sannybot test using Playwright with a chromium webdriver without any specific fix, its value would be set to True and the check would be marked as failed.

While using Playwright with a Chrome instance or undetected-chromedriver, which is a webdriver specifically designed to avoid detection by anti-bots, the check will be marked as passed since the attribute is set to false.
In the GitHub repository available to all readers you find the code to take this test with both the configurations of Playwright and the Undetected Chromedriver but also a way to print programmatically the values of the browser’s attributes.
The navigator.webdriver flag is the low-hanging fruit between the browser’s parameters since it’s the most common one, but I encourage you to check the differences between your browser and your Selenium/Chromium scraper and you’ll notice some small differences which will be the ones that make your scraper detectable.
In case you want to check them by hand on your browser, it’s a quite simple procedure. You need to enter the console in the developer’s tool and start writing “window.navigator”, then press enter. You’ll see all the properties and API functions inside the navigator section.

Browsing around out of the navigator property, you will find a myriad of parameters and functions that describe every detail of your hardware and browser.
Hardware related information
Let’s say you’ve created a scraper that uses Chrome as a browser, so its properties will be the same as a real browser used by a human. When executed on your PC, all the tests are passed and the anti-bot of the target browser lets you scrape its content.
Then, you deploy the same scraper on a datacenter, adding residential proxies to mimic a connection from home, but the anti-bot now blocks you. What’s happening?
The hardware fingerprint is playing its role in detecting your scraper and unless you change your scraping architecture, you can’t go on.
But, it’s also true that with the fingerprinting techniques getting more and more advanced and accurate, new families of browsers gained momentum. Browsers like Brave are more privacy-centric compared to Chrome, giving users more options to camouflage their hardware fingerprints.
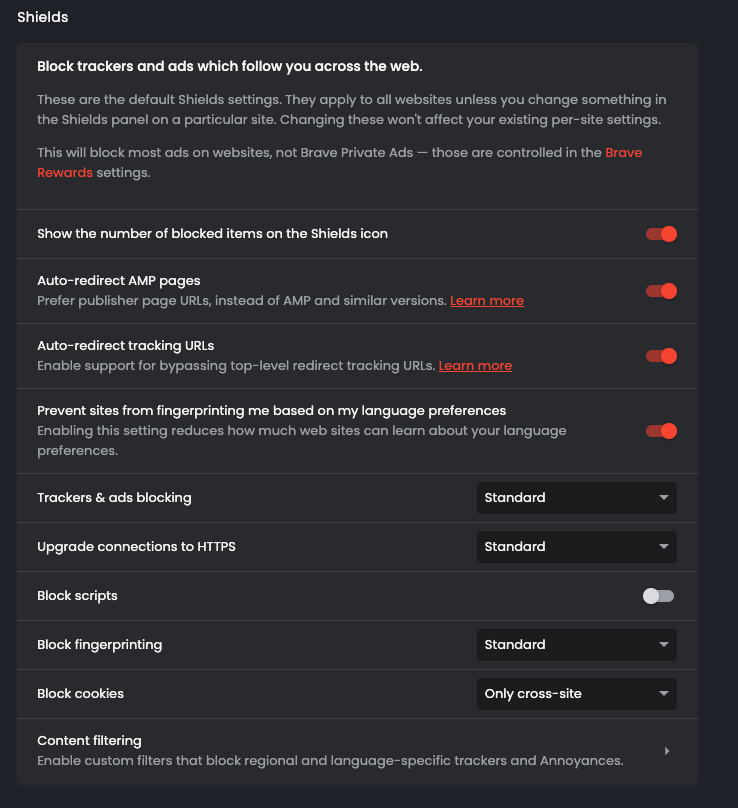
But in case this isn’t enough, there are more privacy-focused browsers called anti-detect. It’s the case with GoLogin, Kameleo, and others where you can create different user profiles with different hardware configurations. In this way, you can create customized hardware fingerprints: as an example, with GoLogin you can customize the number of output video and audio devices and this solution helped me bypass some Cloudflare-protected websites when scraping from data centers.

In fact, servers usually don’t have audio outputs and this can be detected and used as a red flag in the traffic evaluation.
Final remarks
Since every website can be configured differently, according to the anti-bot customization, there’s no secret sauce but only many tries and errors, keeping in mind the following principles:
Mimic human behavior and typical browsing setups
Be gentle with the target website, don’t overload it with requests
Don’t scrape anything you’re not authorized to do: personal information and copyrighted material first.