
Are CAPTCHAs still a thing?
Bypassing CAPTCHAs with AI and the end of the click farms

In the middle of August, a new paper was published about the AI used in resolving CAPTCHAs, and its results caught my eye.
If you don’t want to read the full paper, its conclusions are summarized in this article:
AI bots are so good at mimicking the human brain and vision that CAPTCHAs are useless.
The bots’ accuracy is up to 15% higher than that of humans.
We already talked last Sunday about Cloudflare’s Turnstile, the alternative to Google reCAPTCHA, and how to bypass it with some homemade solution.
This time, we’ll get a bit more detail about CAPTCHAs in general and we’ll see a cheap AI solution that seems to confirm what’s said in the article.
History of CAPTCHA
Let’s start with the name: What does the name CAPTCHA mean? It’s, as you can imagine, an acronym and it stands for “Completely Automated Public Turing test to tell Computers and Humans Apart”.
From the definition, you can understand what’s the purpose of CAPTCHA, a challenge to divide humans from bots, applied to web traffic.
I’ve found different and contradictory statistics about the percentage of the web traffic generated by bots, compared to humans, but on average, we can say that almost half of the traffic happening today on the Web is caused by bots.

But let’s step back again a little: What’s the definition of a Turing test?
the Turing test, originally called the imitation game by Alan Turing in 1950, is a test of a machine's ability to exhibit intelligent behaviour equivalent to, or indistinguishable from, that of a human.
Basically, a machine passes the Turing test if it can perform a task as good as humans would do. An efficient way to divide humans and bots is to create a challenge easy to solve for humans but difficult (or computing-intense) for machines. In the year 2000, when CAPTCHA was born and bots were already an issue, this task was image recognition. Detecting letters and then objects in an image it’s something a human could (and still can) do easily in a few seconds but it was a real challenge for a machine.
Text CAPTCHAs

The first CAPTCHAs, as we said, were born in 2000 and consisted of distorted text, sometimes with colored backgrounds, where users need to write the letters included in the image on a text box.
Soon, it became obvious that this was a huge waste of time and human work since answers to the CAPTCHAs were basically lost after the input.
reCAPTCHA v1
In the same years when CAPTCHAs were born, a crowd-sourced project called Distributed Proofreaders, took its first steps. Its aim was to help the creation of e-texts for Project Gutenberg, a catalog of free e-books created by volunteers, by allowing many people to work together in proofreading drafts of e-texts for errors.
In those days, OCR systems were far from perfect and needed many hours of human supervision. The computer scientist Luis von Ahn (who later became CEO and co-founder of Duolingo), who already worked on the first version of CAPTCHA, had the brilliant idea to merge these two realities and source CAPTCHA’s images with words where OCR systems were uncertain and put the answers of hundreds of millions of persons at work to speed up the digitalization of books.

This new CAPTCHA version has been called reCAPTCHA and was acquired by Google in 2009, which used it for its Google Books project.
reCAPTCHA v2
Year after year OCR techniques became more sophisticated and that meant not only more books scanned but also more reCAPTCHAs automatically solved.
A 2014 study by Google suggested that modern Artificial Intelligence technology could solve even the most distorted of texts with a 99.8% accuracy, and numbers in images with a 90% accuracy.
So CAPTCHAs themselves started using AI applied to behavioral models and device fingerprints to discriminate bots and humans.
It’s basically a box to tick and, according to the user behavior and its fingerprint, a score is assigned. If the user is indicated as legit, he can proceed to the website, otherwise, he’s called to solve more difficult challenges like detecting objects on images, usually taken by Google Streetview.
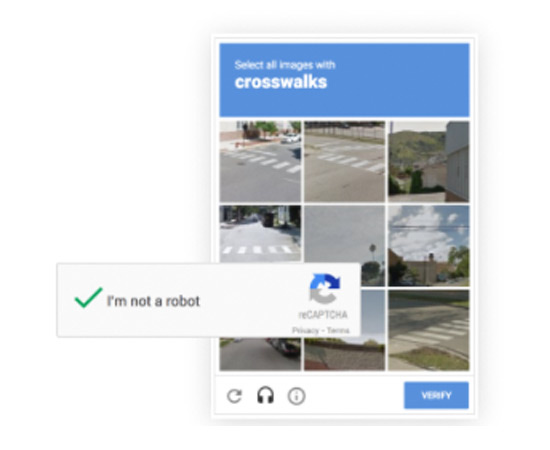
It’s a technique we still very frequently even today, despite the fact that Google released a newer version of reCAPTCHA.
reCAPTCHA v3
We can consider this version of reCAPTCHA, released at the end of 2018, the first version of the noCAPTCHA challenge.
It’s completely transparent to the user and does not require any task to be completed by the user, if he’s considered at low risk of being a bot.
As V2, it relies on AI user behavioral models, cookies, various backend challenges, and device fingerprints to test the “humanity” of the user.
reCAPTCHA alternatives
During this time, other vendors started to compete with Google in this landscape.
We’ve already mentioned Cloudflare’s Turnstile, launched in 2022, which has a similar experience for users to reCAPTCHAs.
We have AWS WAF CAPTCHA (to be honest, I think I’ve never seen one around), always launched in 2022 and requires the user to complete some complex challenges, or hCAPTCHA, a privacy-first open source version of traditional CAPTCHAs with text.
Are CAPTCHAs still used?
With the progress made in recent years with AI, applied both to image and text recognition, the usage of CAPTCHAs as a barrier for bots I’m afraid it’s losing its grip. While they’re still on almost every website to prevent basic bots from spamming, they don’t seem to be an issue anymore when it comes to web scraping. According to this Datadome research, 50% of reCAPTCHAs are solved by… bots (it reminds me of something, don’t you?). This is why several specific anti-bot solutions have been released in the past years to tackle bot traffic in a more advanced way, raising costs and efforts for web scraping projects. More often, these softwares include as a security measure their type of challenges, like the PerimeterX “press and hold button”.
In addition to the competition, more and more tools to bypass CAPTCHAs are being developed, as you can see also from the number of GitHub repositories dedicated to bypassing them using AI.
Another “victim” of AI applied to CAPTCHA solving are also services that use human-powered click-farms to solve them manually. They were the only solution till some years ago but I’ve personally never used them, preferring to find ways to not trigger CAPTCHAs when scraping.
My two main concerns about this kind of service are the poor working conditions of people who spend hours solving CAPTCHAs manually, probably underpaid, and also the technical time to solve them, not always compatible with the web scraping timing.
But despite all their issues and the time passing by, CAPTCHAs are still widely used. According to BuiltWith, out of the first 1 Million websites in the world by traffic, 23% of them still use CAPTCHAs, so it’s still interesting to see how to tackle them.
How to bypass CAPTCHAs in 2023?
I wanted to test some tools to bypass CAPTCHA with AI and after a careful product selection (aka Googling and finding the cheapest one), my choice fell on Nopecha.com.
It has a browser extension, which automatically solves CAPTCHAs on the page, and a Python package to solve them programmatically.
I’ve tested both solutions against reCAPTCHAs and you can find the code in the GitHub repository free for all readers.
After registering on the website and paying for a plan, starting from 5$ per month, you’ll receive an API KEY to use on both the extension and your scripts.
Test browser extension with Playwright
The easiest way I’ve found to test a browser installation with an active extension is to use a persistent context. As a first step, I installed the browser extension by loading a page on the browser, setting a long sleep, and manually installing it.
After doing that, all the following executions will have the extension installed and running, so we can load the page containing the reCAPTCHA V2 challenge and see the magic happen.

In this case, we’re seeing that the reCAPTCHA has some doubts about the source of traffic and throws a more difficult challenge. Instead of only clicking on the “I’m not a robot” box, the program needs to identify bicycles in the images. But this is no longer a problem, and the challenge is solved.
To be honest, I’ve noticed that if the challenge has the button Skip instead of Verify at the bottom of the images, the program enters an endless loop, since it keeps skipping images after selecting them. But this does not change the idea that now it’s getting easy and cheap to bypass this kind of challenge.
Test the Python package with Scrapy
In this case, I’ve integrated the example of the reCAPTCHA V3 bypass available in the API documentation in a Scrapy project.
import scrapy
from scrapy.http import Request
import json
import csv
import nopecha
class BooksscraperSpider(scrapy.Spider):
name = 'capchasolving'
# READING EXTERNAL FILE FOR LOCATIONS
def start_requests(self):
yield Request('https://nopecha.com/demo/recaptcha#easy', callback=self.solve_captcha)
def solve_captcha(self, response):
#sitekey=response.xpath('//div/@data-sitekey').extract()[0]
nopecha.api_key = ''
# Call the Token API
token = nopecha.Token.solve(
type='recaptcha2',
sitekey='6Ld8NA8jAAAAAPJ_ahIPVIMc0C4q58rntFkopFiA',
url='https://nopecha.com/demo/recaptcha#easy',
data={
'action': 'check',
}
)
# Print the token
print(token)
The program returns the token, so the challenge is bypassed and we could go on with scraping the website.
I was not able to do the same on reCAPTCHA V2 but probably this is due to my inexperience with the tool.
In any case, we can see how simple it is to use these tools nowadays, available for every basic standard CAPTCHA available.

Hope you liked this post, feel free to share it with anyone interested
See you next Thursday with another post from The Lab, if you want to receive it in your inbox, subscribe for free.