


Web Scraping experts: Is AI stealing our job?
Spoiler: No, at least not at the moment.

This post is sponsored by Oxylabs, your premium proxy provider. Sponsorships help keep The Web Scraping Free and it’s a way to give back to the readers some value.

In this case, for all The Web Scraping Club Readers, using the discount code WSC25 you can save 25% OFF for your residential proxies buying.
The Generative AI Wave
For the few who went hiking without a phone in the past weeks and didn’t have the chance to scroll their feed on Linkedin, OpenAI released a new version of the GPT-3 model, called ChatGPT.
**Disclaimer: I’m not a super expert on AI, so there could be some inaccurate terms here and there, feel free to write me any mistake you noticed.**
As far as I understood, ChatGPT is a variant of the GPT-3 model, designed explicitly for dialogued interactions. It’s at the moment the most advanced model created, with 10X trainable parameters of the second biggest model existing.
I’ve played around with it and the feeling of talking with an omniscient human in real: you can ask to write a blog post about anything, ask questions and, also, write some code.
Unbelievable, uh?
As said before I’m not an expert so why don’t we ask ChatGPT to explain its functioning to us?
“Tell us a brief history of GPT models”
GPT (Generative Pre-training Transformer) is a type of language model developed by OpenAI. It was introduced in a paper published in 2018 by researchers at OpenAI.
Language models are a type of artificial intelligence that are trained on large amounts of text data to predict the next word in a sequence. They are used in various natural language processing tasks, such as language translation, text generation, and language comprehension.
The original GPT model was a revolutionary development in the field of natural language processing, as it was the first model to demonstrate that it was possible to train a deep learning model to generate human-like text. It was trained on a dataset of billions of words, and it was able to generate coherent and contextually appropriate responses to a wide range of prompts.
Since the introduction of the original GPT model, there have been several updates and improvements to the model. These include GPT-2, which was released in 2019 and was trained on an even larger dataset, and GPT-3, which was released in 2020 and is currently the largest and most powerful language model available.
“And what is Dall-E?”
DALL-E (short for "Deep Learning for Language Generation") is a language generation model developed by OpenAI. It is based on the GPT-3 language model, but it is designed to generate text and images based on a given prompt.
DALL-E works by taking a natural language prompt as input, such as "a two-story pink house with a white fence and a red door," and generating an image that corresponds to the description. It can also generate text descriptions of images, by taking an image as input and generating a description of the image in natural language.
DALL-E was introduced in 2021 and has received a lot of attention due to its ability to generate highly creative and imaginative responses to prompts. It has been used to generate a wide range of images and text descriptions, including objects and scenes that do not exist in the real world.
And it’s exactly what I did to generate the main image of this post, writing in Dall-E “a robot writing some software code sitting on his chair in front of his desk, sci-fi style”

“What are the main differences between GPT-3 and ChatGPT?”
GPT-3 (short for "Generative Pre-training Transformer 3") is a large language model developed by OpenAI, while ChatGPT is a chatbot AI model that is based on GPT-3.
There are several key differences between GPT-3 and ChatGPT:
Purpose: GPT-3 is a general-purpose language model that can be used for a wide range of natural language processing tasks, such as language translation, text generation, and language comprehension. ChatGPT, on the other hand, is specifically designed for chatbot applications and is optimized for generating responses to text input in the form of a conversation.
Training data: GPT-3 is trained on a dataset of billions of words and is designed to generate human-like text. ChatGPT is also trained on a large dataset of text, but it is specifically trained to generate responses to conversational prompts.
Input and output: GPT-3 takes a prompt as input and generates text as output. ChatGPT, on the other hand, takes a conversational exchange as input (i.e., a message from a user and the chatbot's previous response) and generates a response as output.
Functionality: GPT-3 is a generative model that can generate text based on the input it has been given, but it does not have the ability to engage in conversation or respond to specific prompts in a conversational context. ChatGPT, on the other hand, is specifically designed to hold conversations with users and generate responses to prompts in a conversational context.
The interaction is impressive and the quality of the responses is amazing. For sure an AI expert will find them basics and incomplete but for the rest of us, who just want to understand a little about how the world is spinning, they are enough.
And given that in the next months GPT-4 is expected to be rolled out, the AI hype is mounting.
Implications for humans
So at the moment, we’re in front of an AI able to speak any language more or less properly, giving proper human-like answers on almost anything (the scope has been fenced trying to avoid controversial content), that can generate images starting from a description, write code (we’ll see later this aspect), will improve in the future and, for now, it’s also free. Just reading the last sentence, I’ve imagined at least 10 professions that should worry about it.
Imagine you’re writing tons of articles for a website to improve SEO: usually, it’s low/medium quality content but at high volume, to keep the website fresh and updated with the latest trending topics, just like the previous answers given from Chat-GPT.
Also, the answers in Italian are pretty good, you can still understand that are AI-generated from the wording and the translation of terms we would not translate, but for generic topics, we’re almost in the last mile to get a great translation.
And what about Shutterstock and similar websites, with all the creator community behind them? Will have still sense to sell stock images when AI can generate them for free? And what about the digital art market?
Of course, we have no answers here but going back to the topic of this post, should also programmers (and specifically web scrapers) should worry about AI?
Is AI able to code?
Chat-GPT demonstrated in several cases its ability to learn from the training data and understand the underlying patterns that make it adapt this material for new requests.
Let’s see how it behaves in our field, web scraping.
“Create a Scrapy web scraper for Amazon.com”

Followed by some instructions on how to install Scrapy and launch the scraper.
Not a bad result anyway, the scraper is correct and the selectors are almost right, probably are taken from some examples around the web, since I suppose the training data used for ChatGPT was text data and not HTML.
But let’s change something and define selectors and fields. I asked to use scrapy with XPATH selector, to obtain the ASIN code, product title, prices, and product/image URL.
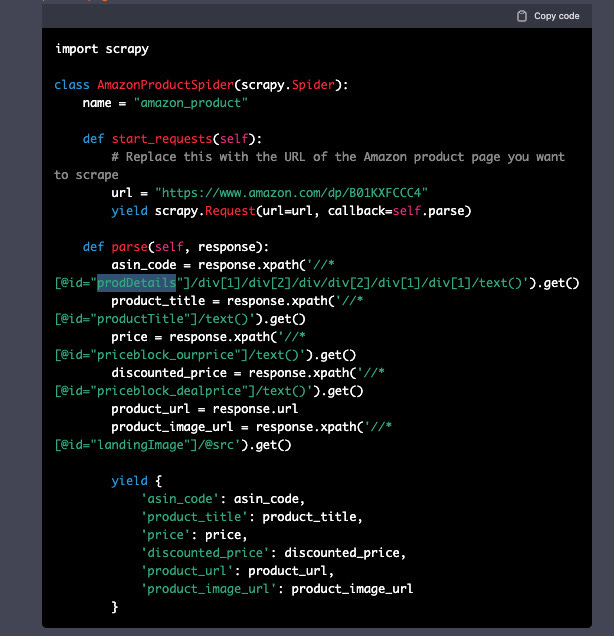
Again, the answer is formally correct, only some of the selectors are not. But it’s not a generic answer, it looks like an answer generated from older answers (ChatGPT is trained with data that stops at 2021) from Stack Overflow or something like that.
“Create a Scrapy web scraper for thewebscraping.club”
As a further confirmation for my theory, I asked a scraper for thewebscraping.club, a website that cannot be scraped in 2021 because it simply did not exist. I wanted again a Scrapy spider that extracts article titles, authors, and image URLs.
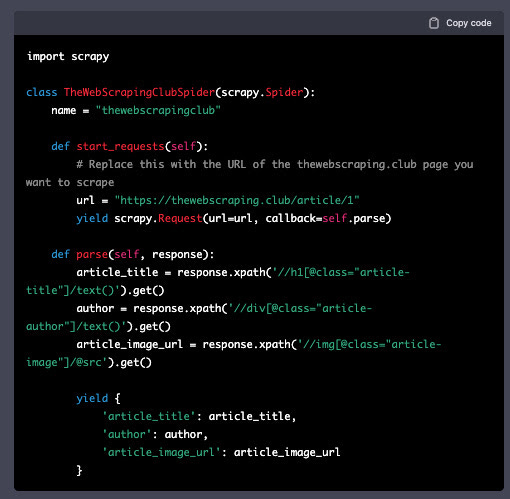
We have a generic Scrapy scraper, with clearly fake XPATHs but is formally correct.
So GPT-3 can write correct code, for sure, but at the moment is not able to analyze and parse the HTML code of the websites to create a 100% working scraper with the right XPATH valid at the moment.
Final remarks
OpenAI is a nonprofit organization and is funded through a combination of donations and sponsorships with billions of dollars. With this GPT-3, DALL-E and ChatGPT raised awareness about the capabilities of AI and, at the same time, the threats that such evolved models can bring.
Possible job losses, as we already mentioned, but also copyright issues. GitHub CoPilot, an AI code completion tool based on OpenAI Codex, is said to answer with code under different licensing, including the MIT, GPL, and Apache licenses, that require attribution to the original authors.
But also with images, if I ask to paint something with Banksy or Van Gogh style, am I downgrading the value of the original creations?


I’m from enough time in the web scraping industry to remember that already 3/4 years ago, some companies were trying to use AI to create web scrapers. Some companies have some solutions around, like Zyte’s Automatic Extraction, and I’m curious about how things evolve.
For sure, with the complexity rising, new anti-bot challenges, and tools to use, coding is more and more marginal in the timeline of a web scraping project.
An AI able to write correct and actual code to scrape a website would help us speed up some phases of our job but all the cat-and-mouse games with anti-bot and the engineering of the requests are far from being solved automatically.
For the moment we’re safe, until when at least a fraction of the investments made in OpenAI is used to “solve the web scraping pain points”.
