
3 THINGS + 1 TO DO BEFORE STARTING CODING YOUR SCRAPER
A checklist to optimize your web scraping routine

Before starting coding your scraper, a good target website analysis could save you a lot of time.
CHECK THE TECHNOLOGY STACK OF THE TARGET WEBSITE
I usually do a double check to have a rapid understanding of the website and to identify known anti-bot solutions.
To do so, I’ve installed the Wappalyzer Chrome Extension, usually, under the security section, there’s an indication of the anti-bot software used.

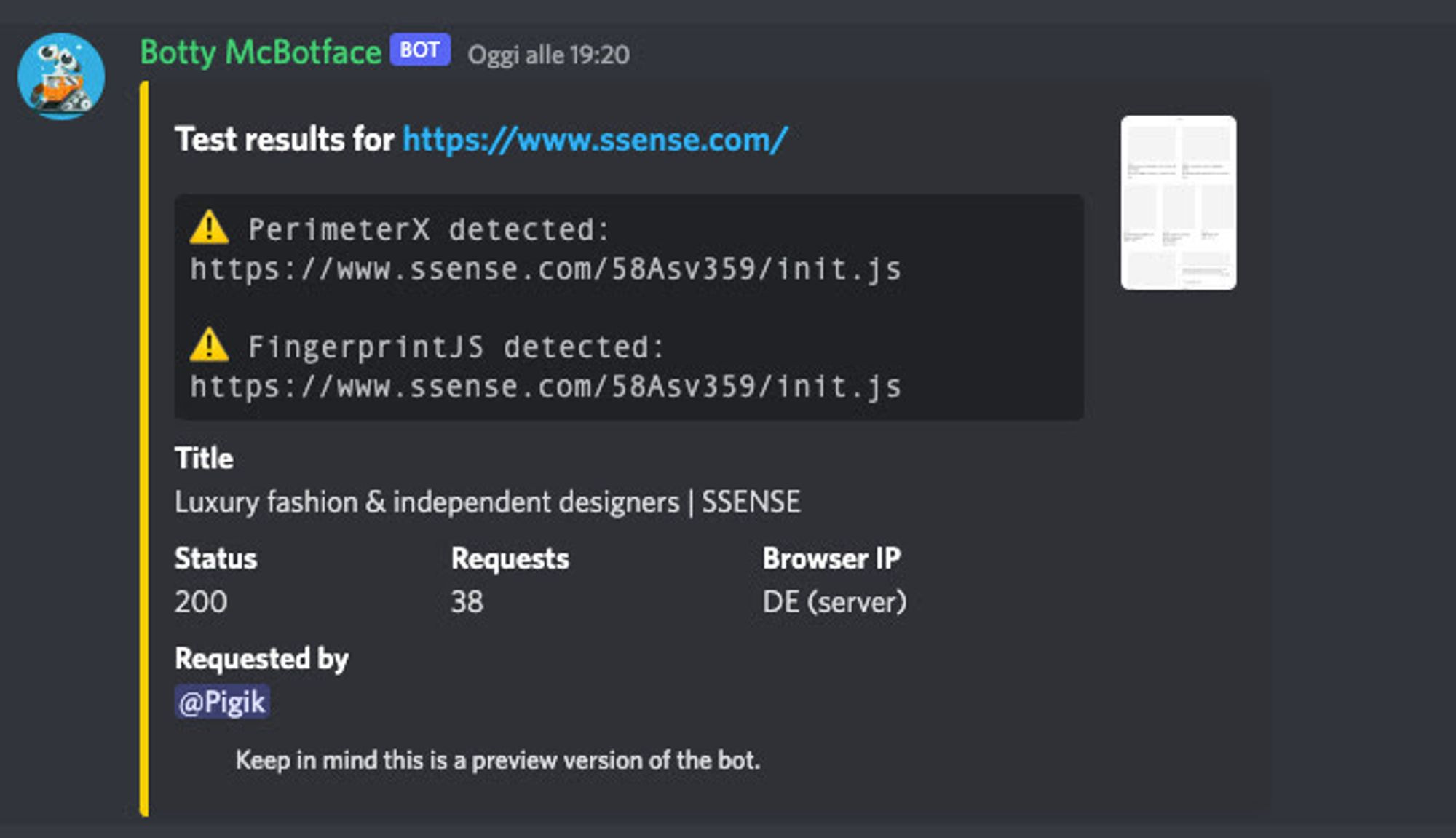
Usually, I double-check the results with a Discord Bot, developed by the team behind Puppeteer, installed inside this server.
In this example, it shows fewer results than the Wappalyzer Extension but when results diverge, this bot is usually right.
LOOK FOR API TO GET DATA FROM
APIs are great friends of web scrapers since they’re much more reliable and less prone to changes over time. Using APIs is also more efficient and this can be an advantage also for the target server.
Looking for API is quite simple, all you need is the Inspect developer tool and tab network. In the case of e-commerce, you can go to the product catalog page and see if, when going from the first page to the second, there’s an API called, like the following example.

In this case, the result is a JSON containing all the products on page 2 of the category accessories for a man. Of course, also the APIs can be protected by anti-bot software so we cannot celebrate yet.
LOOK FOR JSON INSIDE THE HTML
In case API calls are not replicable from the scraper, we could always have a look inside the HTML code of the website and look for JSON formatted data.
We preserve the advantage of using the JSON for scraping, so less prone to changes over time, but it's not as efficient as calling the APIs directly, since we need to load the whole page.

In this case, we have the pagination JSON with all the products displayed inside an HTML tag.
Given these three technical pieces of advice, the next one is the most important.
Ask yourself: "Am I allowed to scrape this website? Am I breaking any law about privacy, infringing any copyright doing so?"
Only after giving yourself the answers, you can proceed (and in the next posts We'll see how to frame correctly the answers since are not always easy to get)
How can I get access to Discord? I was hoping to use that bot, and learn on how to scrape.