
The 2022 recap for the Web Scraping industry
My end of year remarks, the birth of The Web Scraping Club and more

This post is sponsored by Oxylabs, your premium proxy provider. Sponsorships help keep The Web Scraping Free and it’s a way to give back to the readers some value.

In this case, for all The Web Scraping Club Readers, using the discount code WSC25 you can save 25% OFF for your residential proxies buying.
My general feelings about 2022
2022 is closing and as usual, these last days are spent making a recap of what we achieved and what happened during the past year.
As some of you may know from my Linkedin profile, with Re Analytics I’m in the web scraping industry since 2014. Actually, we achieved a dimension of hundreds of e-commerce websites scraped every day so, at least in this niche, I can say I’ve got some experience on the ground.
From my experience, I would say that 2022 is the year where anti-bot solutions gave us the most headaches. The difficulty of web scraping increased significantly and so did the costs of doing it at scale.
But this didn’t stop the web scraping industry, it pushed only the developers to use more sophisticated techniques, more proxies, and headful browsers.
As stated by Shane Evans, CEO of Zyte, during the 2022 Extract Summit, the spending for web data has increased and will continue this trend also in the future.
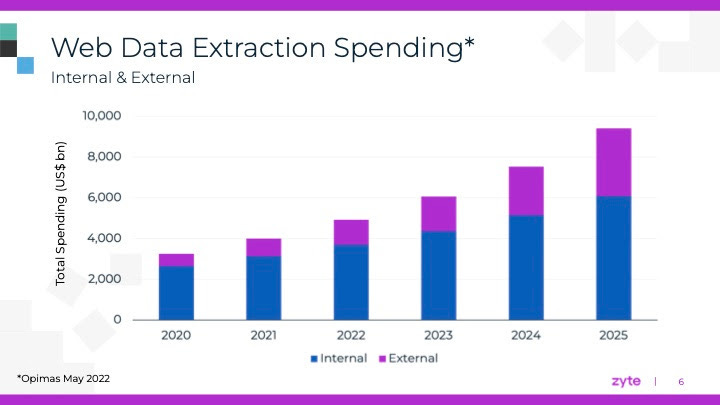
More and more industries are digitalized and so the need and availability of web data keep increasing and so web scraping will be a hot trend for the next years.
Three trends I’ve seen in 2022
Web scraping is getting legal recognition
During 2022 there have been several sentences that established the terms for legal and illegal web scraping.
The US appeal court reaffirmed that HiQ acted correctly in the Linkedin case and the same happened in Korean Supreme Court decisions on cases where companies were scraping competitors’ websites.
Of course, it stays illegal to gather personal data without consent, like Clearview AI did, or breaking consciously the terms of use of the target website.
The rise of AI
During the last 2-3 years I’ve heard about several solutions that use AI to do some web scraping but I’ve always been skeptical about it. It’s such a generic and open task, with lots of variables like anti-bot solutions and different website designs that it seemed to me quite a utopia to have an AI for at least the 90% of the web scraping cases.
But when I’ve seen ChatGPT in action, with such a powerful engine capable to answer almost everything asked, I was shocked. And probably, if such powerful models become more accessible and trainable, we’re close to transforming a utopia into reality.
No Code tools
As for AI, I was skeptical about the adoption of no-code tools, for more or less the same reasons. The web scraping covers a wide array of cases and variables, and on top I wasn’t sure about the scalability of these solutions.
But during 2022 I’ve seen great improvements in these tools, especially if you need to get data from a medium-sized website with no heavy anti-bot software, they could be the most time-to-value effective solutions.
The birth of The Web Scraping Club
When someone asks me why I started The Web Scraping Club, I always answer that was my need at first. I personally needed a place where all the knowledge and experience on the ground I make is written down. Sometimes I spend days looking for a solution to a particular challenge and after solving it, I didn’t want to lose the discoveries, tools, and references I’ve found.
I could do a personal “digital garden”, accessible only to myself, so I could get an advantage of my discoveries. But I strongly believe that building a community with people facing the same issues, encouraging them to exchange solutions, and learning from all of the members has far more advantages than going solo.
For this reason, beside the newsletter, we have our Discord Server, where we can interact and gather all the ideas and challenges we have. I strongly encourage you to join our server, there are some amazing talents with brilliant ideas.
Always because I believe in the power of the community, in 2023 I’d like to add some more contributors to The Web Scraping Club, to cover some more topics I’m not proficient in.
If you have experience in:
Web Scraping in Node.JS
Tools for scraping data from apps
SERP scraping
and want to help the club grow by writing some articles, please reach me at pier@thewebscraping.club
Talking about the growth of the club, we have reached 600 subscribers in only 4 months. I’d like to thank you all personally for the trust you have in me. And a special thanks to the paid subscribers, that helped me to believe in this project and demonstrate your support in such an amazing way.
And of course, I cannot forget to mention Oxylabs, the first company that believed in this newsletter and is giving great support to it and concrete help to our readers. Using the discount code WSC25 you can save 25% OFF for your residential proxies buying.
Spoiler alert: together with Oxylabs, other partners are joining to add value both for the Club and for the readers.
The most-read post of the Club
The growth of The Web Scraping Club is fully organic, I actually don’t spend on advertising and I don’t think I would do it in the near future. So the views are strictly connected to the number of subscribers and how the posts get viral on websites like Hacker News or socials, especially Linkedin or Facebook.
If you think the content you’re reading is meaningful for you and others in your community and want help spreading it, please consider sharing it on these channels.
The first post that got huge success was the first “The Lab” article, which ranked on the first page of Hacker News and has been read by more than 12k people.

I didn’t have the same luck with other posts, HN seems to shadowban you if you post too many times articles from the same website, so I quit sharing with them my article, but please feel free to do it if you want.
Talking about Facebook, I’d like to mention the group Web Scraping World of my friend Wojciech Żeglin, CEO of Dataminers.co
We have the same focus on sharing knowledge on web scraping and suggest entering this group for creating connections with other professionals.
Hope you’re having a good Xmas break holiday, see you soon with a “The Lab” special issue on scraping data from OpenSea.